Lots of things have been in flow since I’ve posted here, but here are few tidbits to explore:
We: Social Spaces for Collaboration
Say that we agree to define collaboration as a group’s ability to coordinate effort to produce some work output. I believe that the effectiveness of collaboration improves in direct proportion to:
- how easy it is to create social spaces in which to do that coordination,
- the degree of composability of those social spaces (especially nesting)
- the variety and utility of the affordances provided in those spaces.
Together let’s call these the claims of Collaborative Power.
Let’s look at some examples:
Version control
Git enables easily creating a social space for coordinating work on a code base. It does this by providing affordances such as; committing, diffing, branching and merging, to assist in that coordination. The affordance of branching is itself an example of Collaborative Power. Within the social space of a code repository, a branch also creates a secondary, simple and secure, social space for further collaboration, or a sub-space. It’s a semantically separate and differentiated place for a sub-group (perhaps of one) to work on the code. This was Git’s “Killer Feature”, branching made trivially cheap.
Channel based messaging
Tools like Discord, Slack and Mattermost make it trivially easy to create the high-level social space of a “Team” or “Server”, and within that, semantically tagged sub-spaces of chat channels. This is analogous to the Repo and Branch levels of VCS systems but for messaging. The ease and low cost of creating social spaces at both of these levels, and the affordances in those spaces (video/audio chat, screen-sharing, bots, etc) make these tools easy to adopt and continue to use.
Generalized Collaborative Power
Is it possible to generalize tooling for Collaborative Power? In other words, what technical affordances would be necessary for creating generalized sub-spaces within a high-level social context?
Imagine being able to create a social space for collaborative work-groups, where what is made trivially easy to instantiate and assemble inside the space, is not one single secondary type of sub-space (i.e. a branch as in a VCS, or a channel in a messaging system) but the mini-apps of your choice, within a simple composible frame.
Enter We
We is a new Holochain app we’re building over at Lightningrod Labs that provides this heightened Collaborative Power. We makes it trivially easy for users to create high-level social spaces and add “applets” to them. These applets provide the functionality for the exact types of collaboration intended by the group.
The UI looks a little like Slack or Discord. There’s a left-hand bar showing your “we-groups”, but instead of the right hand being the channel text stream, there is a secondary bar of “Applets” that have been instantiated into that social space, with the main right-hand window space displaying the UI of one or more of those applets. Here’s a screenshot showing a social space with the Notebooks applet active, which provides a real-time collaborative markdown-editing:
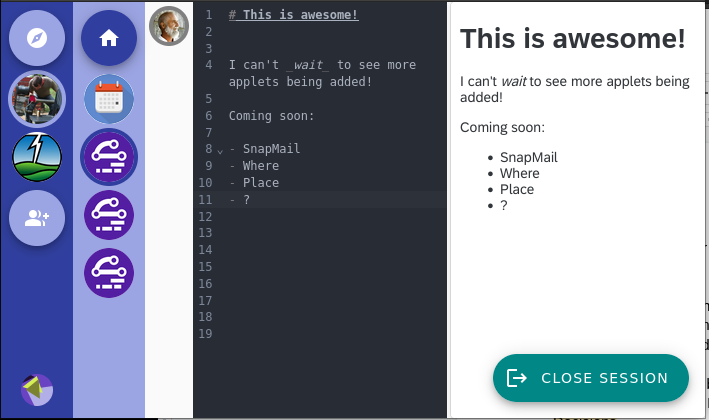
The power of We comes from how easy it is from both a user’s and a developer’s perspective to add new collaboration affordances. End users simply pick them directly in the Applet Library:
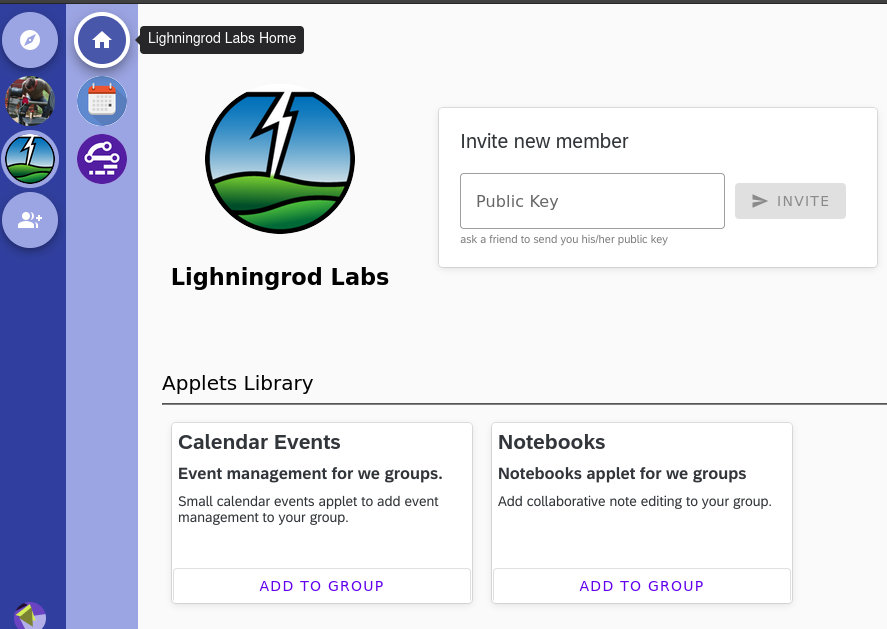
For Holochain hApp developers, this addition makes it very simple to compile, build, and publish to the DevHub their existing hApps as “we-applets”. Then any such hApps become instantly available for composing into We social spaces.
Distributed Groupware
In a way, We might “just” look like another attempt at a groupware tool, but there are few things things that set it apart:
- Generality and Openness: We makes no assumption about the content of collaboration. The affordances of the social spaces are entirely customizable by each group according to the group’s purpose. If a group needs a new social tooling, it can just be added in.
- Decentralization: Although, as mentioned, cheap branching is a key feature of Git, its primary design goal was to make possible a fully distributed version control for the linux operating system, such that no central authority could possibly take ownership of its development. This design is arguably Git’s true super-power; and likewise, because We is built on Holochain, it also provides generalized group-forming capability in the fully distributed context. No central servers or infrastructure is necessary. Simply install the Holochain Launcher and then pick “We” from the App Library.
- Agent-centricity: As a consequence of being built on Holochain, We’s core intent of group collaboration happens from an architecture of empowered agency. Individuals can start groups on-the-fly without request from any authority. Within groups individuals must opt-in to any applet that other agents propose for the group.
Where “We” is going…
The initial release of We demonstrates the key Collaborative Power functionality of adding new applets into social spaces on-the-fly. The next steps come from adding compositional grammatics to applets. These grammatics exist at a few levels:
- Visual: the ability to visually compose applet UIs into complex dashboards/layouts instead of just toggling between monolithic UIs.
- Templating: the ability to create a preset menu of applets that work well together and are easily installable as a group, including their layouts.
- Functional (the 4 “F”s); the ability to evolve social spaces over time:
- Forge: meaning the visual and templating for new group formation.
- Federate: inter-group protocols and connections that allow groups membraned interactions
- Fork: easy spinning up of new groups from existing groups, including data transferability.
- Fuse: easy merging of groups together.
Subsequent releases of We will focus on adding in all these grammatical elements, listed above.
So, back to the claims of Collaborative Power:
Collaboration effectiveness improves in direct proportion to both how easy it is to create nested social spaces in which to do that coordination, and the power of the affordances in those spaces to be recomposed overtime
We provides a significant upgrade to the ease of assembling affordances in social spaces. And it does so while upholding the significant properties of Generality, Decentralization, Agent-Centricity along with providing explicit grammatics for visual assembly, templating and evolution of social spaces.
We hope to see you in We!
P.S: For the technically inclined, hop on over to our github repo and check out the instructions on how to convert your regular hApp to be We ready!
Where and the Grammatics of Location
Consider playing soccer or football blindfolded. Unless you have gotten really good with echolocation, playing the game becomes impossible for the simple reason that you stop being able to answer the questions “where is the ball?” and “where are my teammates?”.
More subtly, consider the difficulties of having hard or delicate conversations using just a pen and slips of paper. The textual medium blindfolds our built-in ability to read facial and tonal emotional cues, thus making it harder to answer the question “where are you emotionally?”. Without them it is less likely that such conversations will come out well.
Collaborative endeavors, like playing soccer or having a conversation, require knowing the locations of the relevant parties in their spaces. As we examine the vast realms of collaboration we see that the ubiquitous need to know “where” both in familiar physical locations, but also in such non-cartesian spaces as education, familiarity, health, happiness, class, wealth, skill, reputation(s), responsibility, intention, completion, etc…
This seems like a fairly straightforward insight. It’s kind of obvious that maps are important to help guide us in achieving our goals in the territory that the map maps. What doesn’t seem obvious to me are the generalized patterns for groups to understand all the different types of spaces that they might want to locate themselves in, and find the grammar of those patterns so as to build new maps on the fly as the new spaces to navigate are recognized and as existing spaces change.
 To begin some exploration of this meta-space we present Where, a simple-as-possible Holochain hApp that equips teams with a tool to create maps and lets team members self-locate on those maps. The underlying Holochain DNA assumes that a Space consists of a coordinate system (more on this below) and various bits of meta-data. Locations in the space are then simply recordings by agents using the coordinate system of the space, along with optional additional data values to add contextual information about any given recording of a location.
To begin some exploration of this meta-space we present Where, a simple-as-possible Holochain hApp that equips teams with a tool to create maps and lets team members self-locate on those maps. The underlying Holochain DNA assumes that a Space consists of a coordinate system (more on this below) and various bits of meta-data. Locations in the space are then simply recordings by agents using the coordinate system of the space, along with optional additional data values to add contextual information about any given recording of a location.
As a starting place we begin with spaces that are just limited to cartesian X,Y coordinates and that all include as meta-data a URL of an image for rendering the “surface” of the space. The initial UI for Where is thus very simple. You can create new maps, move between different maps, zoom them if they are large, and add yourself into the map along with textual tag information to be displayed at that location.
That’s a pretty simple place to start, but I think it’s a powerful grammar for initial exploration. Using somewhat symbolic images like a mountain-scape, or a forest, small groups can attach group-specific meaning to different parts of the image. This is an initial hack for various non-cartesian coordinate systems of dimensionality less than two, like tree structures, or various linear structures (e.g. time-zones), simply by ignoring parts of the 2D space.
Next steps can include:
- Templates that describe the basic structure of a space but allow custom annotations/additions to it
- UIs that can render surfaces of spaces using other coordinate systems: 3D with OpenGL, low dimension tree and graph spaces, Lat.-Long. for geo-spacial maps, 4D spaces (for example 3D + time), and so on.
- Adding the ability to change the surface of spaces over time, not just add locations on them.
- More specific grammars for the meta-data of location entries as they emerge.
- Adding composability of spaces, i.e. locations on surfaces that lead to or render other spaces.
Here is an abstract grammar for Where:
- Nouns:
- Space
- Surface
- Coordinate System
- Meta-data
- Location
- Space
- Coordinate Instance
- Meta-data
- Space
- Verbs:
- Add Space
- Add Location
- Update Location
- Update Space Surface
Like all grammars, the component parts themselves have sub-grammars. For example Coordinate Systems are likely constructed out of a grammar that includes dimensionality, units, and some other rules of valid values. And note that this grammar also includes parts-of-speech, what I’ve labeled “Nouns” and “Verbs”. This is really kind of cheating, because what I’ve called “Nouns” are really Noun-Types, as I haven’t shown any actual Nouns, which would be an actual example of a Space or Location. The “Verbs” really are the only “action-words” of this system, and they are fixed and pretty uninteresting. Kind of like how “conjunctions” are limited to a small set in English.
Though this kind of analysis may be interesting for the computer-scientist/coder/linguists among us, most of us are more interested in the various words, the “vocabulary” of the grammar, and then the conversations that might ensue from using them.
The early development of the ideas for Where came from conversations with Jean Russell about increasing group awareness of typically hidden social landscapes. Here’s one example she offers for a surprisingly simple but really useful space:
Case Study: The “Iron Triangle”
I have struggled, as many of us do, in teams where different people hold the values of the project or organization with different weights. To make this generic and familiar, let’s use the cost, quality, and time triangle. Note that the center is blacked out, since we can’t have some perfect combination of the three.
If the team is dominated by time and cost focused people, then they start resenting the person holding for quality. Or, if focus is on quality, then the resistance shows up to the person focused on delivering on time. Somehow this ends up getting personal rather than the person being regarded as a steward of that value. And the group struggles to come into alignment about priorities and actions.

Note that I have also added, outside the hypotenuse of each angle, the list of consequences people may be trying to avoid by holding that value (at the point of the angle). I believe this too will help others be aware of the risks inherent in not holding to that value.
I am really looking forward to Where as an application I can use with teams to make visible to the group where we each feel the group or project is in the triangle. You could have one where each wants the project to be and another where they think it is now and notice the difference.
I feel like this conversation about the map and placement will move the conversation from individual tension into shared awareness space. It will help us be more compassionate with the person (aka the value) being resisted. It may help people to be heard, better, in their concern and sense the group’s alignment, particularly of the more quiet members. That’s better collective intelligence!

Putting maps like the one in Jean’s example above into Where softens the “Iron” feeling of “pick-two” into a sense-making process where we can better understand how we use the intelligence of the team to collectively come to good answers, simply because we have an opportunity to see what we all see. I feel quite excited to see what other similar maps emerge as really useful to groups, but frankly I’m even more excited to see the secondary grammars that will also emerge. Just like the hashtag was grammatical element introduced to Twitter by one of it’s users, I’m guessing that there are some other similar very simple additions to Where that will carry as much importance and value.
If you are the daring technical type, you can play with Where now by following instructions on the github repo
Maybe next will be Who, What, How and Why!
#grammatics
Decentralized Next-level Collaboration Apps with Syn
Usually I am more energized by building tech than by talking about it, but I am so excited about what my son and I did over winter break, that I just have to share about it here. In an odd kind of busman’s holiday, I spent a good chunk of my time off writing a Holochain application. Coding with my kid is just pure pleasure for me, but I have to describe the additional incredible experience of having spent 4 years building a tool, and now suddenly being able to use that tool to build what it was meant for: creating collaboration applications.
My passion for Holochain has always been sourced in upgrading our collective intelligence, which means making it easier and more joyful to collaborate together. In early December, Art and I sketched out, in an afternoon, a generalized pattern on Holochain for real-time collaborative apps like Google docs where you can type in the same document as others simultaneously, and see their cursor moving around.
Over the holiday break, it took qubist and me just one week to prove out SynText, a peer-to-peer collaborative text editing application
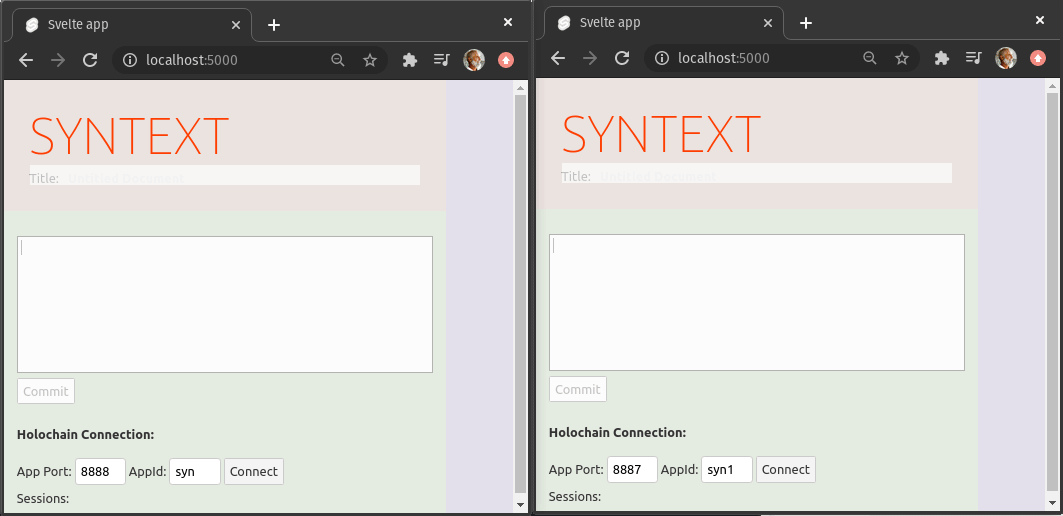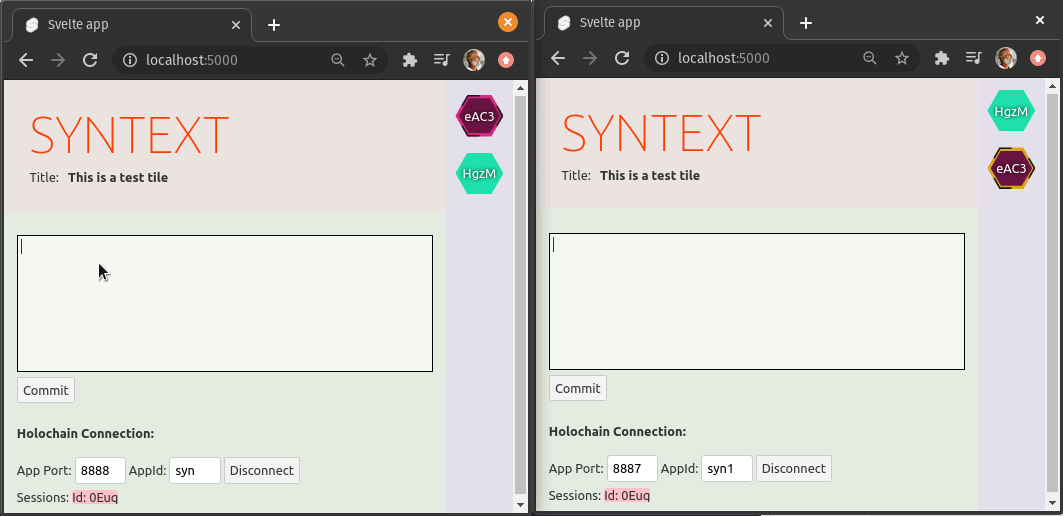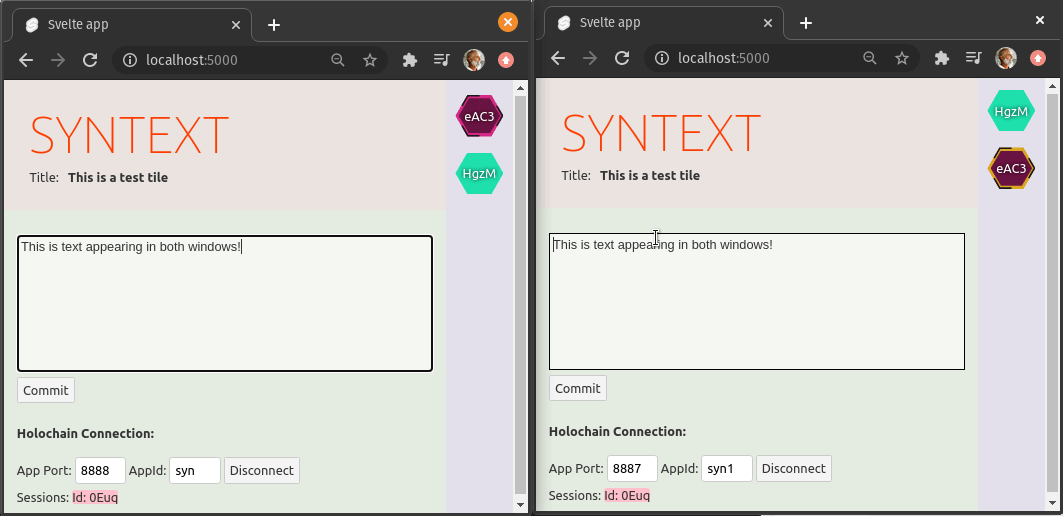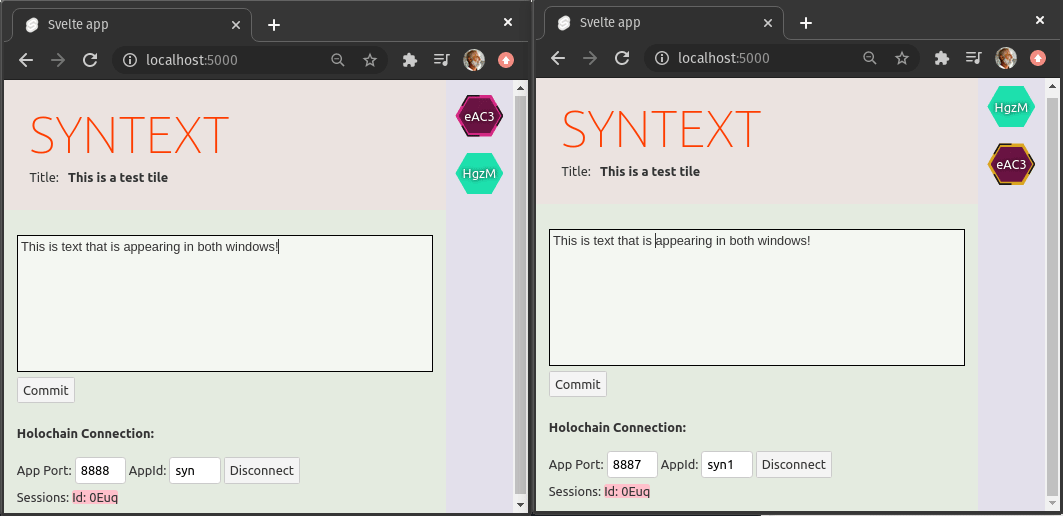
Not only will it be incredibly easy to add other such applications on top of the UI pattern and Holochain DNA that we built, but this pattern will allow git-like branching, forking, and merging, in a user-friendly way for any type of collaborative work, not just code.
My deep excitement in this achievement is two-fold: it’s both practical and also deeply philosophical:
- Syn demonstrates the technical threshold that we’ve crossed in landing Holochain. It was just easy and fast to build it, and things are working like a charm.
- The patterns in the app bring a level of awareness and embodiment of the deep principles of Holochain’s architecture to the forefront. These patterns are all about creating thrivable social-coherence. And by that I mean the kind of social-coherence that arises not from structural coercive centralization, but from peers collaborating by consent. This matters to me.
So, here’s the story about Syn, and bear with me through some back-story because it’s important.
Back-story: Agent-Centric Data Enables Collaboration
If you’ve been following the Holochain/Holo story at all, you’ve probably heard that Holochain is “agent centric.” Strictly speaking this is true, but unfortunately it has hidden a deeper truth about Holochain. Let me explain: we used the term *agent-centric* to distinguish Holochain from other software architectures (especially in the blockchain world) that are philosophically *data-centric*. The prime concern of blockchain ledgers is to create a single “consensus” view on a data reality in the distributed peer-to-peer world, where that’s a known hard problem. In the case of Bitcoin, the idea is to create a data reality of the location of digital coins: who spent them and with whom. In the case of Ethereum, the idea is to create a data reality of not just coin locations, but also the state of a global computer that you can write and run programs on, i.e. “smart-contracts”.
The reason creating these data realities is a hard problem in the decentralized network world is that it’s impossible to determine the absolute ordering of events. This is a simple fact of physics. In the client–server paradigm this isn’t even a problem, because we start from a centralized server where there is a canonical notion of what the data is and a canonical time. The central server stores the data reality. The brilliance of blockchain is that it provides a protocol for distributed peers to hold data reality together, be it the order of transaction of Bitcoins, or the ordering of computation steps on Ethereum. But it does this by enforcing a single ordering of events. The stupidity of blockchain is that the protocol it uses to enforce this single ordering of events is incredibly expensive, extremely wasteful of computation power, and generates obscene amounts of greenhouse gases. On top of all that, for almost all distributed collaborative applications it’s not even necessary to keep one single global ordering of events. It’s easy to make this mistake of thinking so if your purpose is a trust-less system that’s trying to track the location of digital coins, but it turns out that you can still solve that same problem a different way.
| Where is true data? | Ordering of…. | Merge of Perspectives? | |
| Data-Centric, Centralized client-server |
Central server, canonical version | …content is absolute as performed by the central server. | Forced (There is only one central perspective.) |
| Data-Centric, Bitcoin | All peers hold copies of data processed via a validation protocol | …transactions is based on randomized selection of one miner’s sequencing for each block to construct Consensus of token reality. | Forced (One perspective is kept for each block, all others discarded) |
| Data-Centric, Ethereum | All peers hold copies of data processed via validation protocols | …content is based on randomized selection of one miner’s or staker’s sequencing for each block to construct Consensus of a global computer and smart contracts. | Forced (One perspective is kept for each block, all others discarded) |
| Agent-centric, Holochain | Peers hold data they’ve authored, as well as data they’ve validated from other peers. Agents can see or create different realities/times | …content is based on its actual local order, since data is only truly sequential in the experience of an agent. Relative ordering across many people’s local state orderings can be established by explicit protocols and agreements to create shared reality in a case-appropriate way. | Merges only when needed, functions like git. All perspectives are preserved. |
Enter Holochain. The **agent-centric** view point starts from the understanding that data is derived from agency. It does not have “primary” ontological status.
Data is essentially and fundamentally a record of a particular agent’s experience, be that a human, a sensor, or a device. In reality, agents see/sense/detect different things and receive feedback in different orders representing different realities. If any record’s provenance is separated from it, then the “data” represented by that record is fundamentally broken. We can only make sense of data if we know who sensed the data. This is why absolute ordering of massively simultaneous computation is impossible.
But herein lies the “unfortunate” part that I mentioned before. I have seen people jumping on Holochain’s agent-centricity as if it were an ideological stance about the supremacy of individual rights. It is true that the agent-centric approach will help achieve some crucial goals in individual rights, especially around privacy, and preventing inappropriately centralized entities (corporate or governmental) from abusing data privilege. But this is only the first part of the story.
A Holochain application’s architecture is better described as **collaboration-centric**. Start with the reality of agency. Don’t dis-empower these agents. Instead fully empower them to enter into non-coercive play together with agreed upon rule-sets. Then what you get is thrivable social-coherence. This is what Holochain is designed to embody. And it’s working!
So, enough back-story on the philosophy and infrastructure, now for the “front-story.”
Front-Story: Combining the two mother apps of collaboration
So here’s the big deal for me about Syn: It creates the possibility of merging the two most powerful aspects of collaboration software and doing so in the fully decentralized world. This merge, will, I believe have some really interesting consequences, but first the aspects are:
- Real-time multi-user “document” editing
- Alignment of multiple realities: i.e. branching and merging
I’m assuming that point #1 above isn’t controversial, as I will bet that upwards of 75% of everyone reading this has switched from a local word-processor to Google Docs or HackMD for almost all of their text editing.
Point #2 probably ought not be controversial as indicated by the prevalence of git in software development, but it might need a little explanation for those readers that don’t do team coding and therefore aren’t making code commits and branching, forking, and merging many times a day. Even for those of you who are, if you grew up doing so always with your git repos centralized on GitHub, you may be missing a key part of the decentralization story.
For me, the first time I understood what distributed software and peer-to-peer really meant as an architectural reality was when I switched from Subversion to Git for version control. Subversion was based on the mental model of a centralized repository (a database of changes to the code’s text files) from which coders would 1) make local check-outs of that source code 2) edit the files, 3) and then make a commit (which is storing back into the database a set of such changes), but 4) you might have to merge your changes before you could make the commit if someone else had committed first, which entailed resolving any conflicting changes. Coders could also make a branch (which was a copy of the repository) and create a bunch of commits on that branch and merge those in too, but the mental model was still of some central place with a single “canonical” reality that the group of coders was updating.
Git was different. Git assumes no center point. It assumes that each coder has their own copy of the code repository and can pull and push changes to any other distributed copy of the repo they have permission to access. It assumes that all changes are made to local branches and that branches will be created and merged all the time. It embraces locally divergent realities and eventual group consistency.
If you think that your git repository on GitHub is somehow special, well from git’s perspective it isn’t. It’s just a repo that a bunch of agents have agreed to use in a hub-and-spoke synchronization pattern. Your “git push” could be directly to your friends repos if they gave you access and you added them as a remote. In that case you would just be agreeing to a more mesh-like collaboration pattern.
Of course github has loaded lots of collaboration value-add on top of just being a place to embody the hub-and-spoke pattern, with issues, pull requests, kan-ban boards, integrated CI, etc. This is an important part of the story which is part of a pattern that repeats: decentralized public-domain protocols spawn centralized proprietary value-add silos built on top of those protocols. The detailed story of another example of this—about how AOL, GEnie, and Prodigy created chat-rooms, news services and all kinds of proprietary value-add on top of the primary feature of the internet’s SMTP protocol that provided the core service, email—is one I will tell some other time. But the key there is that proprietary value-add was erased by the arrival of another set of open protocols: http and HTML. And I think that Holochain/Syn may be yet another example of this story of the orders-of-magnitude value level-up that happens in this evolutionary process.
I’ll show how in a bit, but first it’s important to understand what it takes to build Syn apps.
To make a Syn app you have to do just a few things:
- Define a state model that represents your application. In the case of a text document this state model might be just two strings, the title and the document body.
- Create patch grammar that defines all the transformations that you can do to the state. In our text doc example that might be just three things: insert a character at a position, remove a character from a position, and set the value of the title.
- Create a delta function which, given a state and a transformation, produces a new state. This is pretty easy to do with simple patch grammars.
- Create a UI that:
- renders the state when it gets notified that the state has changed, and
- creates Syn transformations when the user would like to make a change.
Once you’ve done that, Syn takes care of the heavy lifting of coordinating between all the agents making and synchronizing changes, all without a central server.
That’s aspect 1 from the consequences of collaboration software above:real-time multi-user collaboration. With one additional app-design task, Syn’s architecture also handles aspect 2, Alignment of multiple realities, in a general way:
5. Define a merge strategy for resolving differences between states and transformation sets.
This last task is where things get tricky to do well, and in general can’t always be done in a fully automated way. However, the idea is that when necessary, a merge strategy would include human intervention: manually (i.e. using human judgement) resolving the differences between conflicting change sets. This is nothing new to git users who handle merge conflicts all the time! Note that it’s important that merge strategy is not generalized and specified per-app. This is part of the power of the Syn approach.
Once this fifth task is done, Syn becomes a general framework for adding branching and merging to any collaborative app. At any given time, Syn has the notion of a session, which is just like a branch in git. It’s a commit to treat as a starting point for a series of changes. Unlike Google Docs which just has a single revision history, Syn provides, at the low level, a space for multiple version histories based simply on which session users join and start making changes. With merging, the realities these branches represent can become aligned. Because Syn supports generalized UI for creating/viewing/switching sessions and can insert the merging strategy defined by the particular app, this is a powerful pattern that used to be available only to coders using git. Now, suddenly, it can be applied to arbitrary collaboration apps. In a way, it’s two-level collaboration, synchronously on the “same” state, and asynchronously on divergent/convergent state.
To me this is a big deal. If collaboration is about empowered agents entering into non-coercive playing together by agreed upon rule-sets, then this pattern in Syn is a massive level up meta-rule-set for doing so.
Imagine Wikipedia articles with multiple branches that reflect the true differences we have rather than just being fights in the talk pages, frozen around the assumption that there is a single, neutral point-of-view. And because of their many branches, they can actually merge when people find a way to represent those divergences in ways that can be understood by those who were arguing. That’s next-level collaboration.
Imagine creating branched spreadsheets where each branch models entirely different scenarios off of a core set of assumptions that can then get merged together as reality shows us what happens. That’s next level collaboration.
Imagine the concrete vocabulary of conflict resolution that emerges as we develop new and interesting merge strategies for conflicting change sets in different application contexts. What does it mean to resolve two different color choices applied to the same object by different people in a drawing program? I can imagine an ad-hoc Syn app spinning up that lets people on the fly make proposals and vote, or do rock-paper-scissors, or whatever… all as part of resolving a merge conflict in another Syn app! That’s next level collaboration.
Do you see the implications? I’m excited.
P.S. The holo-hosting team has been using an online-stickies tool to manage choosing topics for our virtual retros. On seeing Syn one of our team members dove right in and got this working in no time:
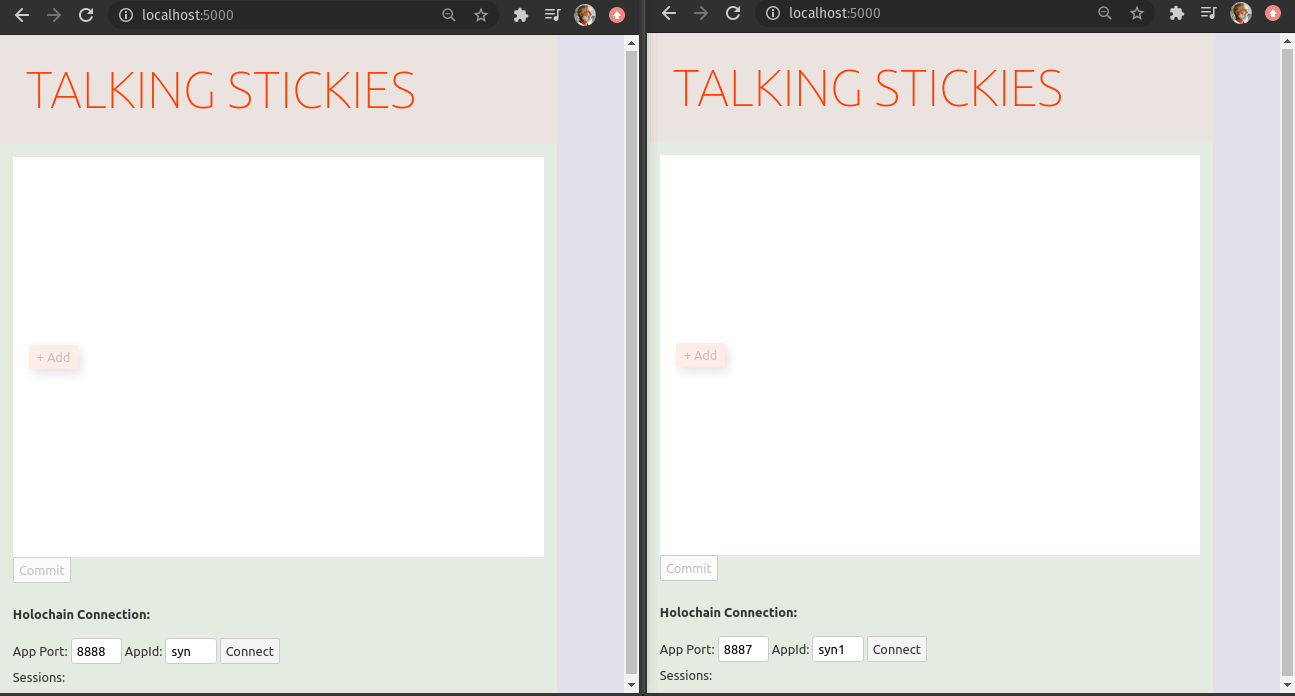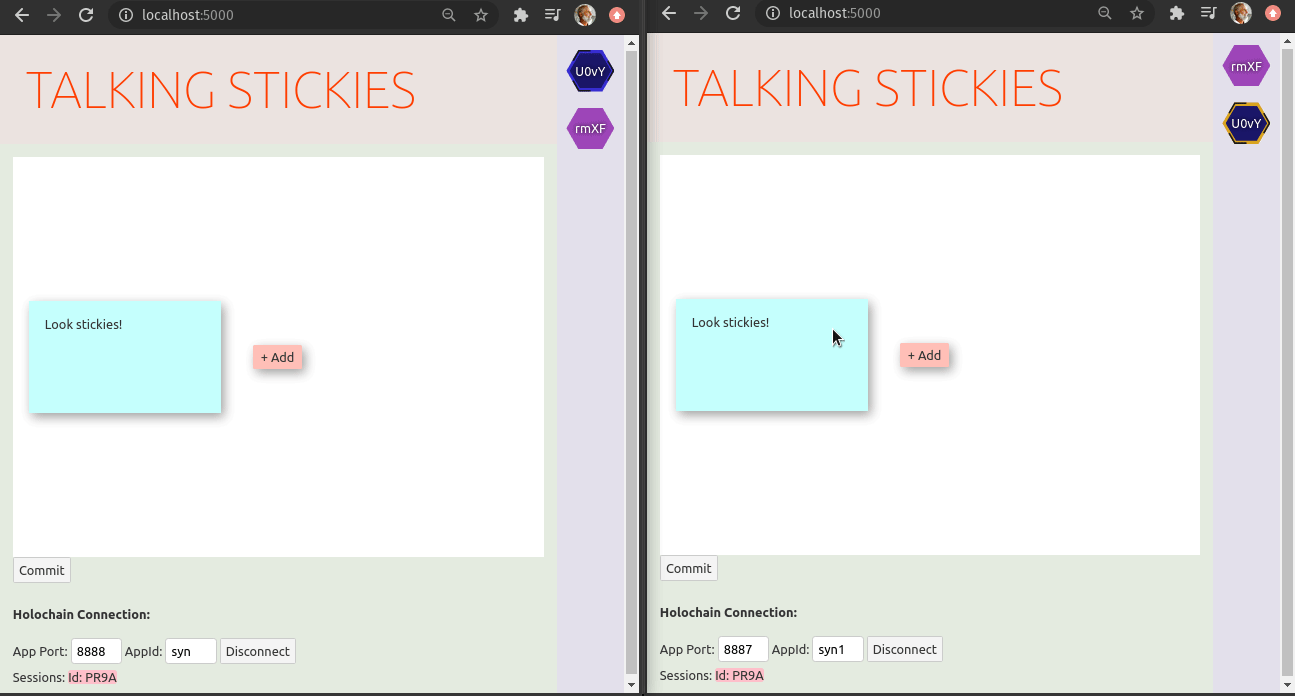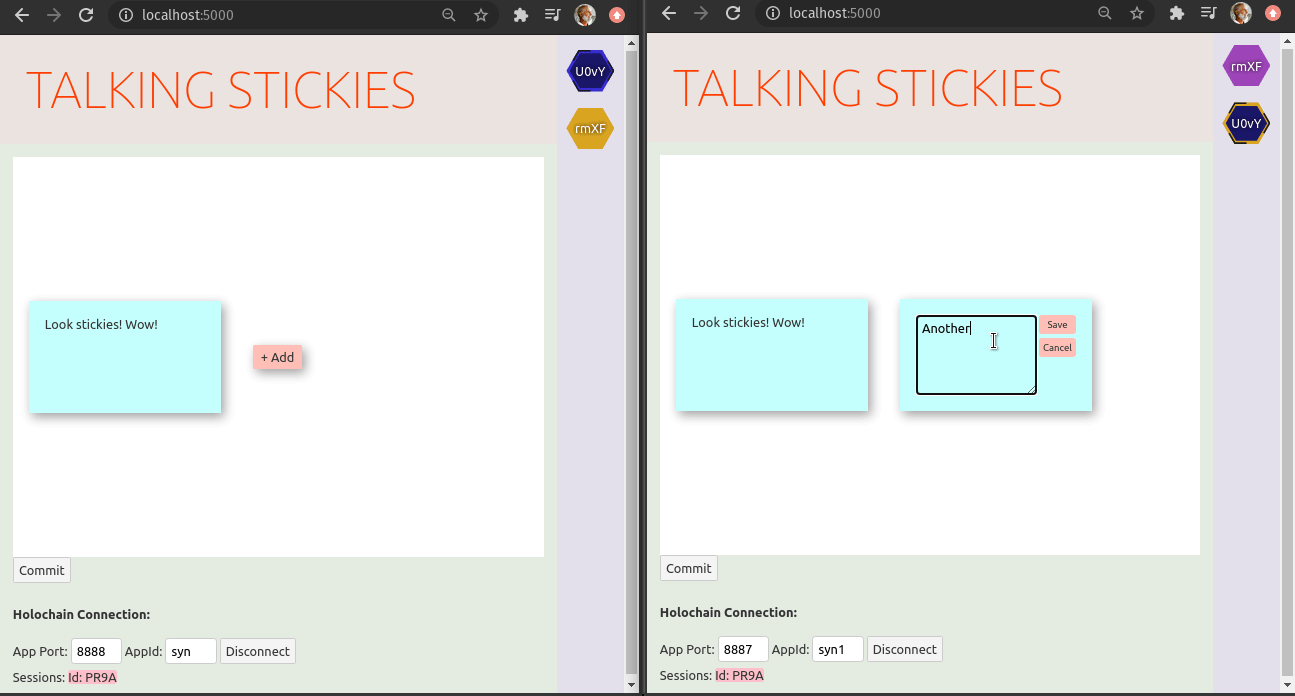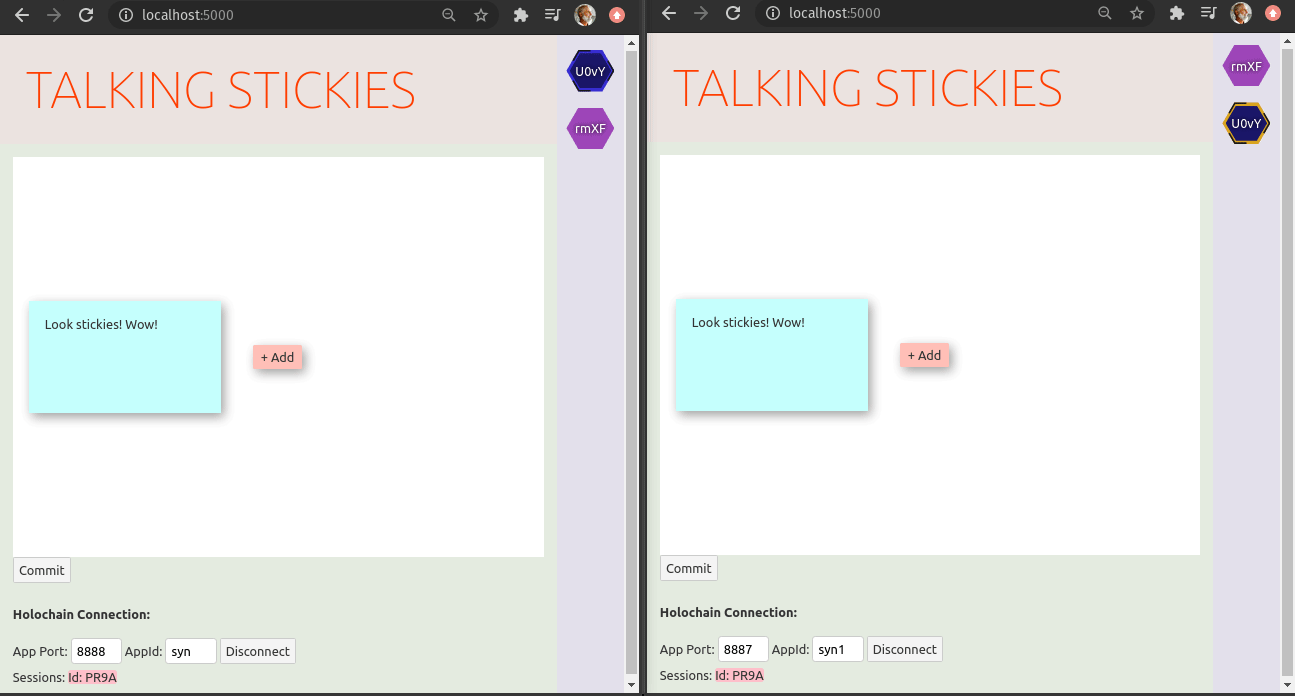 2021-03-03-bundles
2021-03-03-bundlesP.P.S. teaser for the hyper-nerdy reader:

P.P.P.S A number of folks helped with this article: Thanks first of all to Will for being a co-conspirator-in-syn-itself and for detailed edits and clarifications here. Thanks Jean Russell for supporting and pushing me to get this out, and especially for the initial draft of the comparison table. Thanks to Pospi, Guillem Cordoba, Siddharth Sthalekar, Hedayt Abedijoo, Emaline Friedman for comments edits and suggestions that made this article much better. And finally thanks to Art Brock for the usual co-creative sketching of things out that we can then turn into reality.
Supremacy Consciousness, Grammatic Capacity, & Play
As is pretty obvious I don’t write much here. My focus for the last 4 years has been pretty singular on getting Holochain and Holo built. And writing takes me a long time. I also have a hard time writing to the void of the Internet, I need to be in a direct conversation to share well. Recently a friend made an open invitation to respond “about what you’re seeing and thinking in the world right now.” and he provided these prompts:
- What are you seeing more clearly now? What seems less clear or certain to you now than it did previously?
- What are the biggest/most interesting/most urgent open questions on your mind at the moment?
- What issues do you think the world isn’t paying enough attention to?
- What could we be doing that we aren’t doing right now to move towards more positive outcomes for the world? What do you think is standing in the way of us doing that?
Given that we’ve recently crossed some major development thresh-holds in Holochain land, and I’m feeling really positive about where things are going, I felt that I had the spaciousness over my end-of-year break to actually sit down a respond. Here’s what I wrote (along with some images to spice it up):
 I see the “the world” (as you called it) as mostly people living inside a certain form of consciousness (or what’s sometimes called a “dominant meta narrative”) coupled with a slew of embodied forms that work together in a self-perpetuating feedback loop that creates a reasonably stable and coherent set of social organisms that all together we call “society”. I also think the dominant meta-narrative is fairly uniform across the broadest range of cultures on the planet, i.e. it holds true for most of us. I would call this meta-narrative, Supremacy Consciousness, in which humans experience a hierarchy of supremacy, usually putting themselves near the top. This overarching narrative leads to all kinds of the sub-supremacies, human, national, white, male, etc. It creates a reality in which it feels reasonable, even “natural” to create nation-states that colonize the “undiscovered” world. It creates a reality in which it feels reasonable to run an economy on businesses that permanently enclose value while externalizing costs as much as possible. It creates a reality in which it makes sense that our main embodied token on value: Money, has the properties it does: tracking only tradable wealth, issued as debt such that the interest helps catalyze and perpetuate the supremacy hierarchy. It creates a reality in which it makes sense to separate classes, races and genders and order their valuation, and inside this meta-narrative, it makes sense that those orderings are even internalized and held by the people who suffer under them. And by “sense” I don’t mean anything good, I just mean it creates a coherent set of stories and embodied forms that self-perpetuate.
I see the “the world” (as you called it) as mostly people living inside a certain form of consciousness (or what’s sometimes called a “dominant meta narrative”) coupled with a slew of embodied forms that work together in a self-perpetuating feedback loop that creates a reasonably stable and coherent set of social organisms that all together we call “society”. I also think the dominant meta-narrative is fairly uniform across the broadest range of cultures on the planet, i.e. it holds true for most of us. I would call this meta-narrative, Supremacy Consciousness, in which humans experience a hierarchy of supremacy, usually putting themselves near the top. This overarching narrative leads to all kinds of the sub-supremacies, human, national, white, male, etc. It creates a reality in which it feels reasonable, even “natural” to create nation-states that colonize the “undiscovered” world. It creates a reality in which it feels reasonable to run an economy on businesses that permanently enclose value while externalizing costs as much as possible. It creates a reality in which it makes sense that our main embodied token on value: Money, has the properties it does: tracking only tradable wealth, issued as debt such that the interest helps catalyze and perpetuate the supremacy hierarchy. It creates a reality in which it makes sense to separate classes, races and genders and order their valuation, and inside this meta-narrative, it makes sense that those orderings are even internalized and held by the people who suffer under them. And by “sense” I don’t mean anything good, I just mean it creates a coherent set of stories and embodied forms that self-perpetuate.The good news is that this meta-narrative, which has mostly been successfully hidden from view, is becoming more and more apparent. The bad news is that at scale the consequences of the Supremacy Consciousness is self-destruction. This comes largely because the coherence it creates, one of dominance and extraction, has met the real planetary boundaries of both natural and social ecosystem health. The worse news is that the system dynamics in play are, I think, very similar to those of addiction, where all the solutions available to the current embodied forms only make things worse. For example, a core problem of the world is using money to measure value. But almost nobody can envision a world without money, only a world in which money is somehow differently distributed. Even thinking about a “world without money” is mostly considered idealistic political utopic speculation rather than a serious systems theory problem about how to measure and build different classes of value.
Another, perhaps even more simple way to put the above is this: I’m interested in a world where greater collective intelligence is possible. The current underlying patterns of collective intelligence, although pretty darn incredible in some respects, are leading us to collective suicide at scale, which I’d like to avoid.
So then, what’s to be done? What creates greater collective intelligence? What, in the words of your prompts “could we be doing that we aren’t doing right now to move towards more positive outcomes for the world? What do you think is standing in the way of us doing that?”
Here’s the story of _what_ I’m doing to that end, _why_ it makes sense to me, _how_ I’m going about it, including the _blockers_ I see in getting there and what might be done about them:
What: I believe the world needs a new grammatic capacity. We need a _grammar_ that can express social organisms with as much complexity and composibility as that provided by the grammar we call DNA for expressing biological life. We need the embodied _capacity_ to bring them into being with as much ease as the cell has in cranking out assembling the protein complexes and expressed in genes.
How: So, if we need a new grammatic capacity that works for representing, and expressing social organisms into being, how do we go about that? Well, let’s look at grammatic capacities in general. What are they like?
First, the powerful fundamental ones all look like a stack built out of, guess what, other grammatic capacities. Stories, the high level expressions the grammatic capacity we call Language, are built out of paragraphs, which our built out of sentences, which are built out of sentence fragments, which are built out of words, which are built out word-parts, which are build out phonemes, which are built out phones. Each of these levels have their own distinct grammatic integrity which are related to the capacity in play for expressing and receiving the grammatical units at that level.
 Biological organisms are built out of protein complexes, so it makes sense that the lowest level code in DNA is for single amino-acids such that virtually any kind of protein complexes can be built. This demonstrates another key aspect of grammatic capacities: they provide a template for composibility of fundamental parts. What are Social organisms built out of? We can certainly argue about this, but, at least roughly speaking, they appear to me to be built out of agreement complexes. Sometimes people call these “social contracts.” Thus, it seems likely that the lowest level of our grammatic capacity should code for “micro-agreements” in a way that allows them to be composed.
Biological organisms are built out of protein complexes, so it makes sense that the lowest level code in DNA is for single amino-acids such that virtually any kind of protein complexes can be built. This demonstrates another key aspect of grammatic capacities: they provide a template for composibility of fundamental parts. What are Social organisms built out of? We can certainly argue about this, but, at least roughly speaking, they appear to me to be built out of agreement complexes. Sometimes people call these “social contracts.” Thus, it seems likely that the lowest level of our grammatic capacity should code for “micro-agreements” in a way that allows them to be composed.Another way of looking at such “micro-agreements” in the social space is that they are patterns for interaction between agents that allows the agents to come into alignment on a shared reality, what we can call a Protocol. Protocols are exactly these patterns for interactions between agents. They are templates that create shared contexts so that we can understand each other better and more efficiently. We are all very familiar with both formal and informal protocols, from the pattern of a Pilots repeating back what Air-traffic-controllers say, to the patterns of thank-you-you-are-welcome of politeness, to Diplomatic protocols of behavior at state dinners, these are all little micro-agreements that allow us to act within a pre-defined shared context instead of having to hash everything out in each interaction.
So, our new grammatic capacity then would provide a grammar for creating and composing such Protocols, such that it’s easy for groups of people to build larger agreement complexes out of them. Here’s where things get fun. A Protocol as just defined is just another way of talking about a grammatic capacity: DNA provides the protocol stack for cell agents to align on a shared genetic reality and build organisms together. Language provides the protocol stack for human agents to align on a shared expressivity reality and build meaning together. If so the grammatic capacity we need is one in which we can create grammatic capacities. A Protocol for Protocols.
So that’s the focus of all my endeavors. How to do that in big and small ways. Gameshifting as used in Agile Learning Centers is an example. It’s a protocol for knowing and shifting which social protocol is in play. The MetaCurrency Project, Ceptr and Holochain are all about bringing this into the world for use at scale.
A final note about “How” and this has to do with “blockers”. The how of landing such a protocol for protocols matters. There are different global scale social dynamics that will arise depending on whether this grammatic capacity is owned or enclosed, vs if it’s held as a commons. If the carriers on which the signals in the grammar are sent are owned, then then that creates a huge power-imbalance. Thus, the unenclosability of the fundamental carriers of the grammatic capacity makes a huge difference in what will evolve there. The deep pattern of enclosure that’s built into the capitalist approach is a huge blocker to making this all land in the world. There’s a lot more to say about this, but I think this is long enough for now.
 To end this screed, I’d like to come back to the beginning and connect grammatic capacities to Supremacy Consciousness. Achieving supremacy always relies on coercion of one sort or another. Violence is the word we use for coercion on the physical level. We also recognize other forms of non-physical coercion as violent, or at least we call it abusive. We recognize coercive manipulation of media and information, “Fake News” etc. These are all practices inside Supremacy Consciousness.
To end this screed, I’d like to come back to the beginning and connect grammatic capacities to Supremacy Consciousness. Achieving supremacy always relies on coercion of one sort or another. Violence is the word we use for coercion on the physical level. We also recognize other forms of non-physical coercion as violent, or at least we call it abusive. We recognize coercive manipulation of media and information, “Fake News” etc. These are all practices inside Supremacy Consciousness.So the other way seems fairly clear. If I base all my actions in the spirit of non-coercive conversation, I will be living outside of Supremacy Consciousness. So many things I do require coercion of others. Extracting myself from the coercive life is non-trivial. But I believe that in the end, this will feel, interestingly, like play. As James P. Carse says in Finite and Infinite Games: “he who must play, cannot play”. Play cannot happen inside the context of coercion. But play is also all about temporarily creating finite boundaries, and rules by which to enter into consentfull play. And this is the role of the Protocol for Protocols. It could be, by consent, a temporary game for creating more temporary games, knowing that we will always want to expand the horizons of our game playing together.
The App: from Killer to Mother
 The Wikipedia defines “Killer App” as a marketing term for “any computer program that is so necessary or desirable that it proves the core value of some larger technology.” Not surprising that the term comes from marketing, that branch of business devoted to competing for customers and trying to kill off the competition. But if we remove ourselves from the context of dog-eat-dog, and then start from that definition and work backwards to come up with a single word that it defines, well, “killer” hardly seems right. “Mother” fits much better. Those applications that seed the growth of whole new realms, we ought to call Mother Apps.
The Wikipedia defines “Killer App” as a marketing term for “any computer program that is so necessary or desirable that it proves the core value of some larger technology.” Not surprising that the term comes from marketing, that branch of business devoted to competing for customers and trying to kill off the competition. But if we remove ourselves from the context of dog-eat-dog, and then start from that definition and work backwards to come up with a single word that it defines, well, “killer” hardly seems right. “Mother” fits much better. Those applications that seed the growth of whole new realms, we ought to call Mother Apps.
VisiCalc, the first spreadsheet app, often gets used as the prime example of a Killer App. Lots of folks bought Apple II computers just so they use VisiCalc. More broadly e-mail (as a category of App) frequently gets nominated as the Killer App for the Internet. Pretty obviously nothing was killed in either of these examples but lots got birthed. More recently the term Killer App has become diluted in common usage to mean any indispensable computer program. Just try typing into google “X is the killer app”, and substitute for x with Facebook, Twitter, Instagram, etc, and you’ll see what I mean.
But I find it really useful to maintain that distinction of source or spring-board. So I offer this definition of “Mother App”: a computer program (or class of program) that uses a technology in a new way to both reveal and unleash its power.” I hope it catches on!
Current-see and Death Straight Talk
I haven’t written much lately, I guess I’ve been busy… mostly with two things: Cancer & Ceptr.
Currently, my time is about living with a spouse with stage 4 metastatic breast cancer and all that it takes to support her as well I can. My work is about building tools for a post-monetary society; creating a new meta-language to allow a vast expansion in social forms that is currently limited primarily by the world’s current statement of value: money. These two worlds have recently come together in ways worth writing about.
Wh en describing my work-in-the-world, people are always asking me for more examples. Because abstract descriptions like the one in the paragraph above don’t really do it for folks. I get it. But it’s hard for me! When what you are designing is like grammar for a kind of language that doesn’t exist, it’s pretty hard to give examples of sentences in that language, because it doesn’t exist yet! But there are openings into what that language looks like and what it might feel like to “speak” it. Here’s the one that comes from the intersection of my two lives. It’s called DST (Death Straight Talk).
en describing my work-in-the-world, people are always asking me for more examples. Because abstract descriptions like the one in the paragraph above don’t really do it for folks. I get it. But it’s hard for me! When what you are designing is like grammar for a kind of language that doesn’t exist, it’s pretty hard to give examples of sentences in that language, because it doesn’t exist yet! But there are openings into what that language looks like and what it might feel like to “speak” it. Here’s the one that comes from the intersection of my two lives. It’s called DST (Death Straight Talk).
First, go and read my post about DST on Ellen’s cancer blog. There I share the concrete personal story, when you get back here I’ll tell the current-see story that connects it to my work:
In the post-monetary world, value coordination isn’t reduced to a unidimensional bottom-line of money. We actually already live with one foot in that world. We are swimming in non-monetary current-sees like grades, credits, degrees, e-bay/Amazon/Uber ratings, food certifications of all sorts (USDA Organic, Fair-Trade, Non-GMO, etc)–the list goes on. We just normally don’t recognize them as “parts-of-speech” in a single “language.” When we do, new things become possible.
This is what happened to me around DST. Pretty much everywhere I go now I look at the world through the lens of seeing all the information token systems we use to coordinate our actions. Movie and train tickets are current-sees, so are postage stamps, and buy-10-get-1-free coffee cards, intake-forms, passports, and licenses, the list goes on and on. I look for the current-see life-cycle, the issuer, the redeemer, other co-functioning current-sees, and I look for the level of wealth the current-see corresponds to in our living systems model of wealth.
{kind=link}
In December, Ellen got diagnosed with malignant pleural and pericardial effusions, which required hospitalization to get drains inserted to relieve fluid buildup in the sacs around her lung and heart (cancer cells muck up the usual flow paths). While in the hospital a protocol around a slightly lowered blood sodium level involved giving her “some fluids.” Seemed innocent enough. Well, in Ellen’s case, those IV fluids ended up causing pretty extreme swelling in her feet (she renamed her feet manatees). The swelling was bad enough on its own, but due to neuropathy from previous chemotherapy, meant that thereafter walking was almost impossible due to the pain in her feet. It took three weeks for the swelling to go down, and for Ellen to do more than hobble. This had a cascade effect on loss of muscle which still hasn’t returned.
It’s pretty clear to me that the protocol that triggered the IV fluids didn’t take into account increased swelling risk, that, it turns out, comes from protein loss from pleural fluid drainage. I really doubt it took into account added pain due to neuropathy. And I know for certain that it didn’t take into account quality-of-life assessment around the questions of balancing risk of loss of mobility for a person possibly in the last months of their life, because no-one asked.
At the end of January, I went to California to help co-facilitate a workshop on Deep Wealth Design principles. On the last day of my trip, I got word that Ellen was back in the hospital again. After the previous hospitalization we had talked lots, and felt pretty good, about how to communicate with the medical world about her specific risk around IV fluids to prevent immobilization by swelling. But this time around there was much more going on. The short version: I could tell that lots of hospital protocols weren’t going to take into account Ellen’s situation, and what she wanted given her prognosis of limited life span.
Then it hit me, probably because I was primed by the workshop: Medical staff have a current-see that they know how to pay attention to, the Do-Not-Resuscitate order (DNR). And it’s issued by the patient! I knew we need something like that, and that I had to have an acronym to refer to it. That’s how DST came to be. The rest of the story you know from my post on Ellen’s blog, but from a current-see perspective here’s the take-home: Adding a token issued by the patient allows re-evaluation of risks built into other protocols based on that patient’s stated understanding of what will create well-being for them.
Note that DST so far isn’t a real current-see, because, unlike a DNR, there’s no social agreement on its issuance, use and life-cycle. But just my words to nurses “pretend like she has a DST sticker in her chart” made it work as if it were. It connected the main current-see hospital staff has to work with, the chart, with Ellen’s particular place in the flow. It’s a pretty powerful example of the effect of current-sees on social systems, and my own beloved’s well-being in the midst of them.
I want this story to give you a visceral sense of how the social body gets built out of the formal information tokens we create Yes, underneath it’s the humans and their compassion and love and all that great gushy stuff that really matters. But the social body is built out of communication tokens and the agreements around their use –things like DST. We will lose what really matters if we don’t understand this. When we understand it, really and deeply, then we will also develop a kind of “language”, that can all “speak” to allow us to spin up various DST-like current-sees, and to evolve them on the fly.
When we have that new “language,” then we will have stepped fully into the post-monetary world. That’s why I work on Ceptr and the MetaCurrency project.