Lots of things have been in flow since I’ve posted here, but here are few tidbits to explore:
coding/software
We: Social Spaces for Collaboration
Say that we agree to define collaboration as a group’s ability to coordinate effort to produce some work output. I believe that the effectiveness of collaboration improves in direct proportion to:
- how easy it is to create social spaces in which to do that coordination,
- the degree of composability of those social spaces (especially nesting)
- the variety and utility of the affordances provided in those spaces.
Together let’s call these the claims of Collaborative Power.
Let’s look at some examples:
Version control
Git enables easily creating a social space for coordinating work on a code base. It does this by providing affordances such as; committing, diffing, branching and merging, to assist in that coordination. The affordance of branching is itself an example of Collaborative Power. Within the social space of a code repository, a branch also creates a secondary, simple and secure, social space for further collaboration, or a sub-space. It’s a semantically separate and differentiated place for a sub-group (perhaps of one) to work on the code. This was Git’s “Killer Feature”, branching made trivially cheap.
Channel based messaging
Tools like Discord, Slack and Mattermost make it trivially easy to create the high-level social space of a “Team” or “Server”, and within that, semantically tagged sub-spaces of chat channels. This is analogous to the Repo and Branch levels of VCS systems but for messaging. The ease and low cost of creating social spaces at both of these levels, and the affordances in those spaces (video/audio chat, screen-sharing, bots, etc) make these tools easy to adopt and continue to use.
Generalized Collaborative Power
Is it possible to generalize tooling for Collaborative Power? In other words, what technical affordances would be necessary for creating generalized sub-spaces within a high-level social context?
Imagine being able to create a social space for collaborative work-groups, where what is made trivially easy to instantiate and assemble inside the space, is not one single secondary type of sub-space (i.e. a branch as in a VCS, or a channel in a messaging system) but the mini-apps of your choice, within a simple composible frame.
Enter We
We is a new Holochain app we’re building over at Lightningrod Labs that provides this heightened Collaborative Power. We makes it trivially easy for users to create high-level social spaces and add “applets” to them. These applets provide the functionality for the exact types of collaboration intended by the group.
The UI looks a little like Slack or Discord. There’s a left-hand bar showing your “we-groups”, but instead of the right hand being the channel text stream, there is a secondary bar of “Applets” that have been instantiated into that social space, with the main right-hand window space displaying the UI of one or more of those applets. Here’s a screenshot showing a social space with the Notebooks applet active, which provides a real-time collaborative markdown-editing:
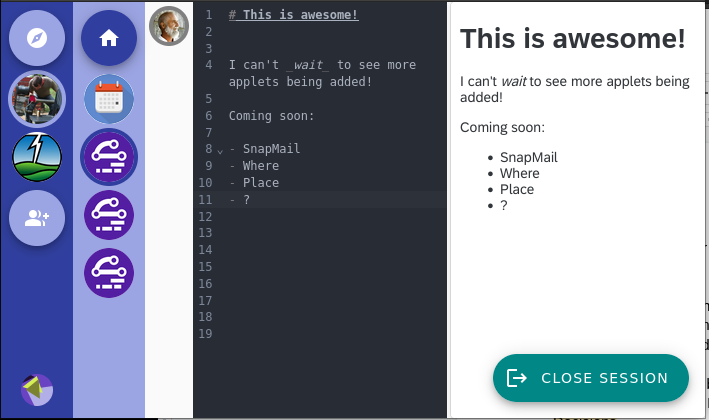
The power of We comes from how easy it is from both a user’s and a developer’s perspective to add new collaboration affordances. End users simply pick them directly in the Applet Library:
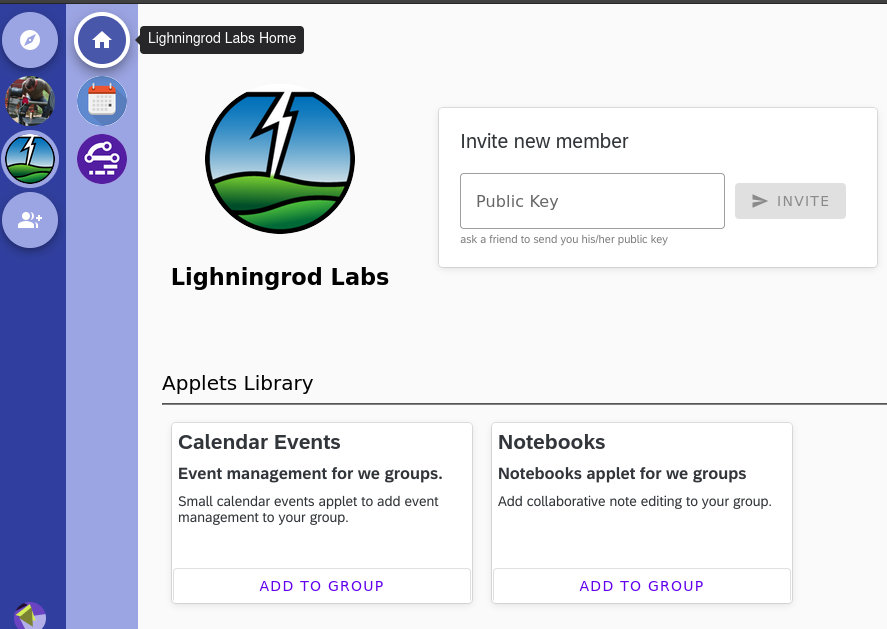
For Holochain hApp developers, this addition makes it very simple to compile, build, and publish to the DevHub their existing hApps as “we-applets”. Then any such hApps become instantly available for composing into We social spaces.
Distributed Groupware
In a way, We might “just” look like another attempt at a groupware tool, but there are few things things that set it apart:
- Generality and Openness: We makes no assumption about the content of collaboration. The affordances of the social spaces are entirely customizable by each group according to the group’s purpose. If a group needs a new social tooling, it can just be added in.
- Decentralization: Although, as mentioned, cheap branching is a key feature of Git, its primary design goal was to make possible a fully distributed version control for the linux operating system, such that no central authority could possibly take ownership of its development. This design is arguably Git’s true super-power; and likewise, because We is built on Holochain, it also provides generalized group-forming capability in the fully distributed context. No central servers or infrastructure is necessary. Simply install the Holochain Launcher and then pick “We” from the App Library.
- Agent-centricity: As a consequence of being built on Holochain, We’s core intent of group collaboration happens from an architecture of empowered agency. Individuals can start groups on-the-fly without request from any authority. Within groups individuals must opt-in to any applet that other agents propose for the group.
Where “We” is going…
The initial release of We demonstrates the key Collaborative Power functionality of adding new applets into social spaces on-the-fly. The next steps come from adding compositional grammatics to applets. These grammatics exist at a few levels:
- Visual: the ability to visually compose applet UIs into complex dashboards/layouts instead of just toggling between monolithic UIs.
- Templating: the ability to create a preset menu of applets that work well together and are easily installable as a group, including their layouts.
- Functional (the 4 “F”s); the ability to evolve social spaces over time:
- Forge: meaning the visual and templating for new group formation.
- Federate: inter-group protocols and connections that allow groups membraned interactions
- Fork: easy spinning up of new groups from existing groups, including data transferability.
- Fuse: easy merging of groups together.
Subsequent releases of We will focus on adding in all these grammatical elements, listed above.
So, back to the claims of Collaborative Power:
Collaboration effectiveness improves in direct proportion to both how easy it is to create nested social spaces in which to do that coordination, and the power of the affordances in those spaces to be recomposed overtime
We provides a significant upgrade to the ease of assembling affordances in social spaces. And it does so while upholding the significant properties of Generality, Decentralization, Agent-Centricity along with providing explicit grammatics for visual assembly, templating and evolution of social spaces.
We hope to see you in We!
P.S: For the technically inclined, hop on over to our github repo and check out the instructions on how to convert your regular hApp to be We ready!
Decentralized Next-level Collaboration Apps with Syn
Usually I am more energized by building tech than by talking about it, but I am so excited about what my son and I did over winter break, that I just have to share about it here. In an odd kind of busman’s holiday, I spent a good chunk of my time off writing a Holochain application. Coding with my kid is just pure pleasure for me, but I have to describe the additional incredible experience of having spent 4 years building a tool, and now suddenly being able to use that tool to build what it was meant for: creating collaboration applications.
My passion for Holochain has always been sourced in upgrading our collective intelligence, which means making it easier and more joyful to collaborate together. In early December, Art and I sketched out, in an afternoon, a generalized pattern on Holochain for real-time collaborative apps like Google docs where you can type in the same document as others simultaneously, and see their cursor moving around.
Over the holiday break, it took qubist and me just one week to prove out SynText, a peer-to-peer collaborative text editing application
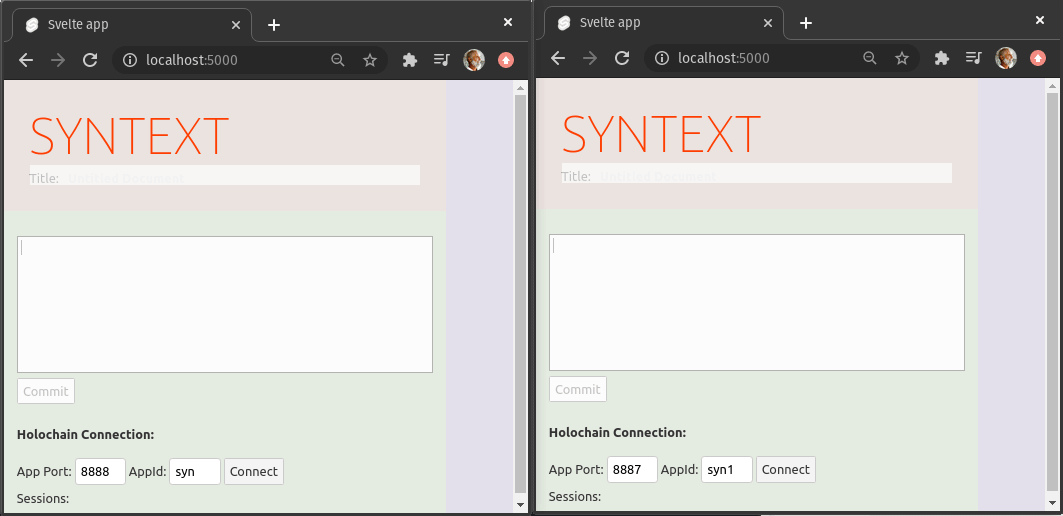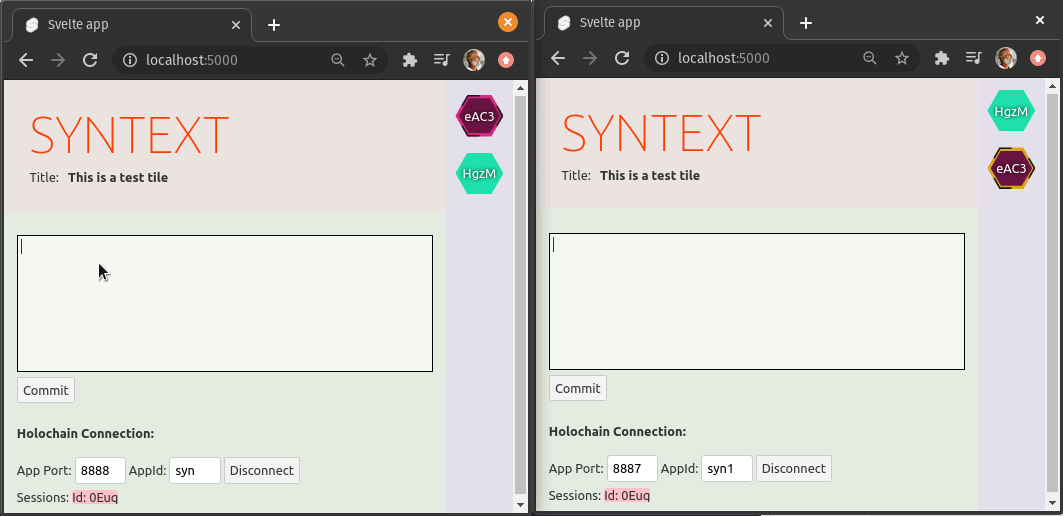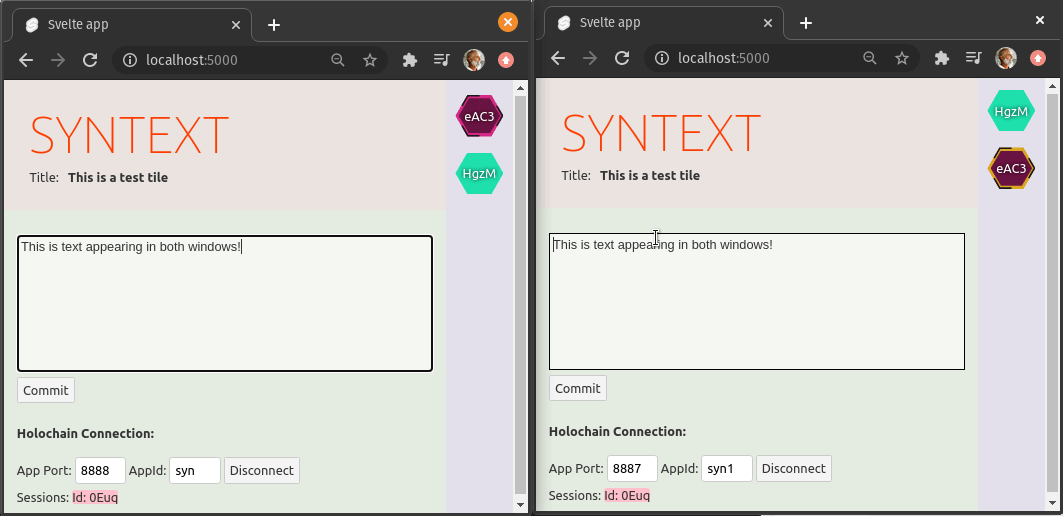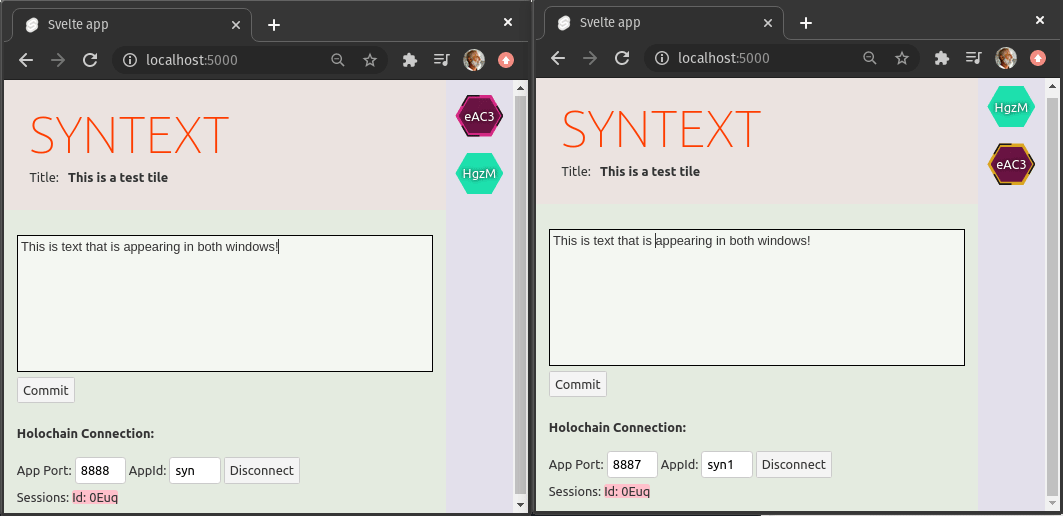
Not only will it be incredibly easy to add other such applications on top of the UI pattern and Holochain DNA that we built, but this pattern will allow git-like branching, forking, and merging, in a user-friendly way for any type of collaborative work, not just code.
My deep excitement in this achievement is two-fold: it’s both practical and also deeply philosophical:
- Syn demonstrates the technical threshold that we’ve crossed in landing Holochain. It was just easy and fast to build it, and things are working like a charm.
- The patterns in the app bring a level of awareness and embodiment of the deep principles of Holochain’s architecture to the forefront. These patterns are all about creating thrivable social-coherence. And by that I mean the kind of social-coherence that arises not from structural coercive centralization, but from peers collaborating by consent. This matters to me.
So, here’s the story about Syn, and bear with me through some back-story because it’s important.
Back-story: Agent-Centric Data Enables Collaboration
If you’ve been following the Holochain/Holo story at all, you’ve probably heard that Holochain is “agent centric.” Strictly speaking this is true, but unfortunately it has hidden a deeper truth about Holochain. Let me explain: we used the term *agent-centric* to distinguish Holochain from other software architectures (especially in the blockchain world) that are philosophically *data-centric*. The prime concern of blockchain ledgers is to create a single “consensus” view on a data reality in the distributed peer-to-peer world, where that’s a known hard problem. In the case of Bitcoin, the idea is to create a data reality of the location of digital coins: who spent them and with whom. In the case of Ethereum, the idea is to create a data reality of not just coin locations, but also the state of a global computer that you can write and run programs on, i.e. “smart-contracts”.
The reason creating these data realities is a hard problem in the decentralized network world is that it’s impossible to determine the absolute ordering of events. This is a simple fact of physics. In the client–server paradigm this isn’t even a problem, because we start from a centralized server where there is a canonical notion of what the data is and a canonical time. The central server stores the data reality. The brilliance of blockchain is that it provides a protocol for distributed peers to hold data reality together, be it the order of transaction of Bitcoins, or the ordering of computation steps on Ethereum. But it does this by enforcing a single ordering of events. The stupidity of blockchain is that the protocol it uses to enforce this single ordering of events is incredibly expensive, extremely wasteful of computation power, and generates obscene amounts of greenhouse gases. On top of all that, for almost all distributed collaborative applications it’s not even necessary to keep one single global ordering of events. It’s easy to make this mistake of thinking so if your purpose is a trust-less system that’s trying to track the location of digital coins, but it turns out that you can still solve that same problem a different way.
| Where is true data? | Ordering of…. | Merge of Perspectives? | |
| Data-Centric, Centralized client-server |
Central server, canonical version | …content is absolute as performed by the central server. | Forced (There is only one central perspective.) |
| Data-Centric, Bitcoin | All peers hold copies of data processed via a validation protocol | …transactions is based on randomized selection of one miner’s sequencing for each block to construct Consensus of token reality. | Forced (One perspective is kept for each block, all others discarded) |
| Data-Centric, Ethereum | All peers hold copies of data processed via validation protocols | …content is based on randomized selection of one miner’s or staker’s sequencing for each block to construct Consensus of a global computer and smart contracts. | Forced (One perspective is kept for each block, all others discarded) |
| Agent-centric, Holochain | Peers hold data they’ve authored, as well as data they’ve validated from other peers. Agents can see or create different realities/times | …content is based on its actual local order, since data is only truly sequential in the experience of an agent. Relative ordering across many people’s local state orderings can be established by explicit protocols and agreements to create shared reality in a case-appropriate way. | Merges only when needed, functions like git. All perspectives are preserved. |
Enter Holochain. The **agent-centric** view point starts from the understanding that data is derived from agency. It does not have “primary” ontological status.
Data is essentially and fundamentally a record of a particular agent’s experience, be that a human, a sensor, or a device. In reality, agents see/sense/detect different things and receive feedback in different orders representing different realities. If any record’s provenance is separated from it, then the “data” represented by that record is fundamentally broken. We can only make sense of data if we know who sensed the data. This is why absolute ordering of massively simultaneous computation is impossible.
But herein lies the “unfortunate” part that I mentioned before. I have seen people jumping on Holochain’s agent-centricity as if it were an ideological stance about the supremacy of individual rights. It is true that the agent-centric approach will help achieve some crucial goals in individual rights, especially around privacy, and preventing inappropriately centralized entities (corporate or governmental) from abusing data privilege. But this is only the first part of the story.
A Holochain application’s architecture is better described as **collaboration-centric**. Start with the reality of agency. Don’t dis-empower these agents. Instead fully empower them to enter into non-coercive play together with agreed upon rule-sets. Then what you get is thrivable social-coherence. This is what Holochain is designed to embody. And it’s working!
So, enough back-story on the philosophy and infrastructure, now for the “front-story.”
Front-Story: Combining the two mother apps of collaboration
So here’s the big deal for me about Syn: It creates the possibility of merging the two most powerful aspects of collaboration software and doing so in the fully decentralized world. This merge, will, I believe have some really interesting consequences, but first the aspects are:
- Real-time multi-user “document” editing
- Alignment of multiple realities: i.e. branching and merging
I’m assuming that point #1 above isn’t controversial, as I will bet that upwards of 75% of everyone reading this has switched from a local word-processor to Google Docs or HackMD for almost all of their text editing.
Point #2 probably ought not be controversial as indicated by the prevalence of git in software development, but it might need a little explanation for those readers that don’t do team coding and therefore aren’t making code commits and branching, forking, and merging many times a day. Even for those of you who are, if you grew up doing so always with your git repos centralized on GitHub, you may be missing a key part of the decentralization story.
For me, the first time I understood what distributed software and peer-to-peer really meant as an architectural reality was when I switched from Subversion to Git for version control. Subversion was based on the mental model of a centralized repository (a database of changes to the code’s text files) from which coders would 1) make local check-outs of that source code 2) edit the files, 3) and then make a commit (which is storing back into the database a set of such changes), but 4) you might have to merge your changes before you could make the commit if someone else had committed first, which entailed resolving any conflicting changes. Coders could also make a branch (which was a copy of the repository) and create a bunch of commits on that branch and merge those in too, but the mental model was still of some central place with a single “canonical” reality that the group of coders was updating.
Git was different. Git assumes no center point. It assumes that each coder has their own copy of the code repository and can pull and push changes to any other distributed copy of the repo they have permission to access. It assumes that all changes are made to local branches and that branches will be created and merged all the time. It embraces locally divergent realities and eventual group consistency.
If you think that your git repository on GitHub is somehow special, well from git’s perspective it isn’t. It’s just a repo that a bunch of agents have agreed to use in a hub-and-spoke synchronization pattern. Your “git push” could be directly to your friends repos if they gave you access and you added them as a remote. In that case you would just be agreeing to a more mesh-like collaboration pattern.
Of course github has loaded lots of collaboration value-add on top of just being a place to embody the hub-and-spoke pattern, with issues, pull requests, kan-ban boards, integrated CI, etc. This is an important part of the story which is part of a pattern that repeats: decentralized public-domain protocols spawn centralized proprietary value-add silos built on top of those protocols. The detailed story of another example of this—about how AOL, GEnie, and Prodigy created chat-rooms, news services and all kinds of proprietary value-add on top of the primary feature of the internet’s SMTP protocol that provided the core service, email—is one I will tell some other time. But the key there is that proprietary value-add was erased by the arrival of another set of open protocols: http and HTML. And I think that Holochain/Syn may be yet another example of this story of the orders-of-magnitude value level-up that happens in this evolutionary process.
I’ll show how in a bit, but first it’s important to understand what it takes to build Syn apps.
To make a Syn app you have to do just a few things:
- Define a state model that represents your application. In the case of a text document this state model might be just two strings, the title and the document body.
- Create patch grammar that defines all the transformations that you can do to the state. In our text doc example that might be just three things: insert a character at a position, remove a character from a position, and set the value of the title.
- Create a delta function which, given a state and a transformation, produces a new state. This is pretty easy to do with simple patch grammars.
- Create a UI that:
- renders the state when it gets notified that the state has changed, and
- creates Syn transformations when the user would like to make a change.
Once you’ve done that, Syn takes care of the heavy lifting of coordinating between all the agents making and synchronizing changes, all without a central server.
That’s aspect 1 from the consequences of collaboration software above:real-time multi-user collaboration. With one additional app-design task, Syn’s architecture also handles aspect 2, Alignment of multiple realities, in a general way:
5. Define a merge strategy for resolving differences between states and transformation sets.
This last task is where things get tricky to do well, and in general can’t always be done in a fully automated way. However, the idea is that when necessary, a merge strategy would include human intervention: manually (i.e. using human judgement) resolving the differences between conflicting change sets. This is nothing new to git users who handle merge conflicts all the time! Note that it’s important that merge strategy is not generalized and specified per-app. This is part of the power of the Syn approach.
Once this fifth task is done, Syn becomes a general framework for adding branching and merging to any collaborative app. At any given time, Syn has the notion of a session, which is just like a branch in git. It’s a commit to treat as a starting point for a series of changes. Unlike Google Docs which just has a single revision history, Syn provides, at the low level, a space for multiple version histories based simply on which session users join and start making changes. With merging, the realities these branches represent can become aligned. Because Syn supports generalized UI for creating/viewing/switching sessions and can insert the merging strategy defined by the particular app, this is a powerful pattern that used to be available only to coders using git. Now, suddenly, it can be applied to arbitrary collaboration apps. In a way, it’s two-level collaboration, synchronously on the “same” state, and asynchronously on divergent/convergent state.
To me this is a big deal. If collaboration is about empowered agents entering into non-coercive playing together by agreed upon rule-sets, then this pattern in Syn is a massive level up meta-rule-set for doing so.
Imagine Wikipedia articles with multiple branches that reflect the true differences we have rather than just being fights in the talk pages, frozen around the assumption that there is a single, neutral point-of-view. And because of their many branches, they can actually merge when people find a way to represent those divergences in ways that can be understood by those who were arguing. That’s next-level collaboration.
Imagine creating branched spreadsheets where each branch models entirely different scenarios off of a core set of assumptions that can then get merged together as reality shows us what happens. That’s next level collaboration.
Imagine the concrete vocabulary of conflict resolution that emerges as we develop new and interesting merge strategies for conflicting change sets in different application contexts. What does it mean to resolve two different color choices applied to the same object by different people in a drawing program? I can imagine an ad-hoc Syn app spinning up that lets people on the fly make proposals and vote, or do rock-paper-scissors, or whatever… all as part of resolving a merge conflict in another Syn app! That’s next level collaboration.
Do you see the implications? I’m excited.
P.S. The holo-hosting team has been using an online-stickies tool to manage choosing topics for our virtual retros. On seeing Syn one of our team members dove right in and got this working in no time:
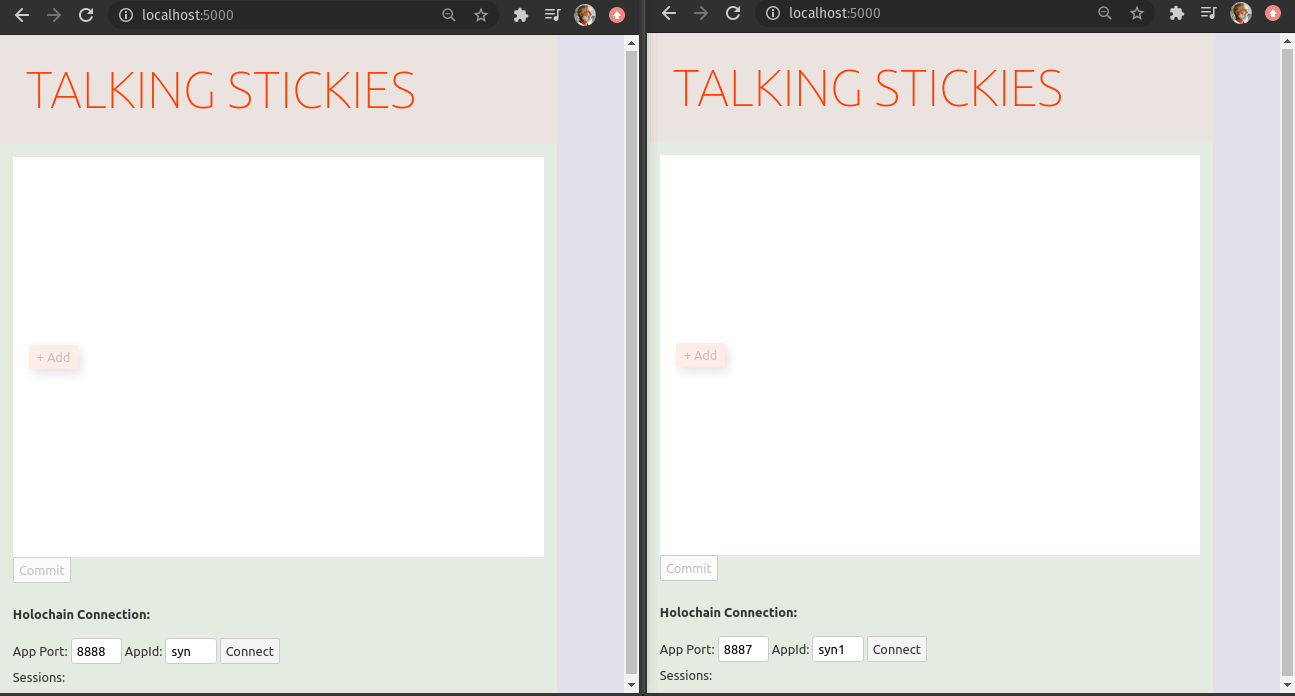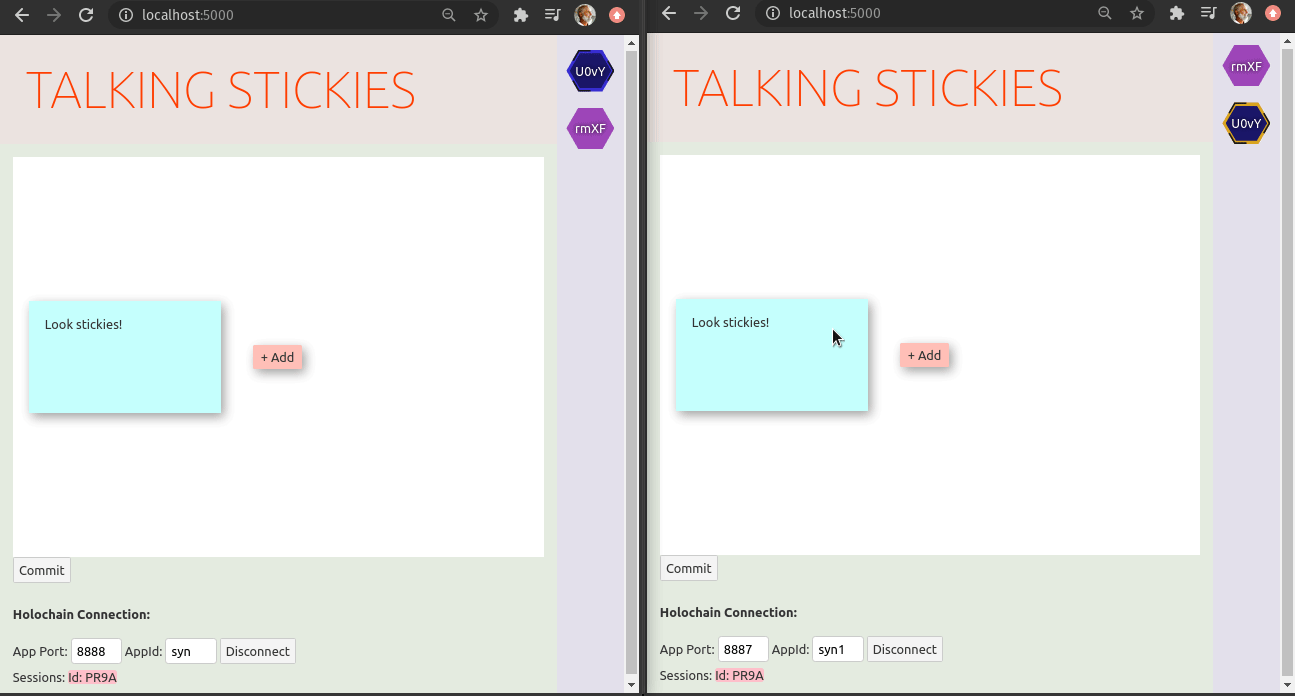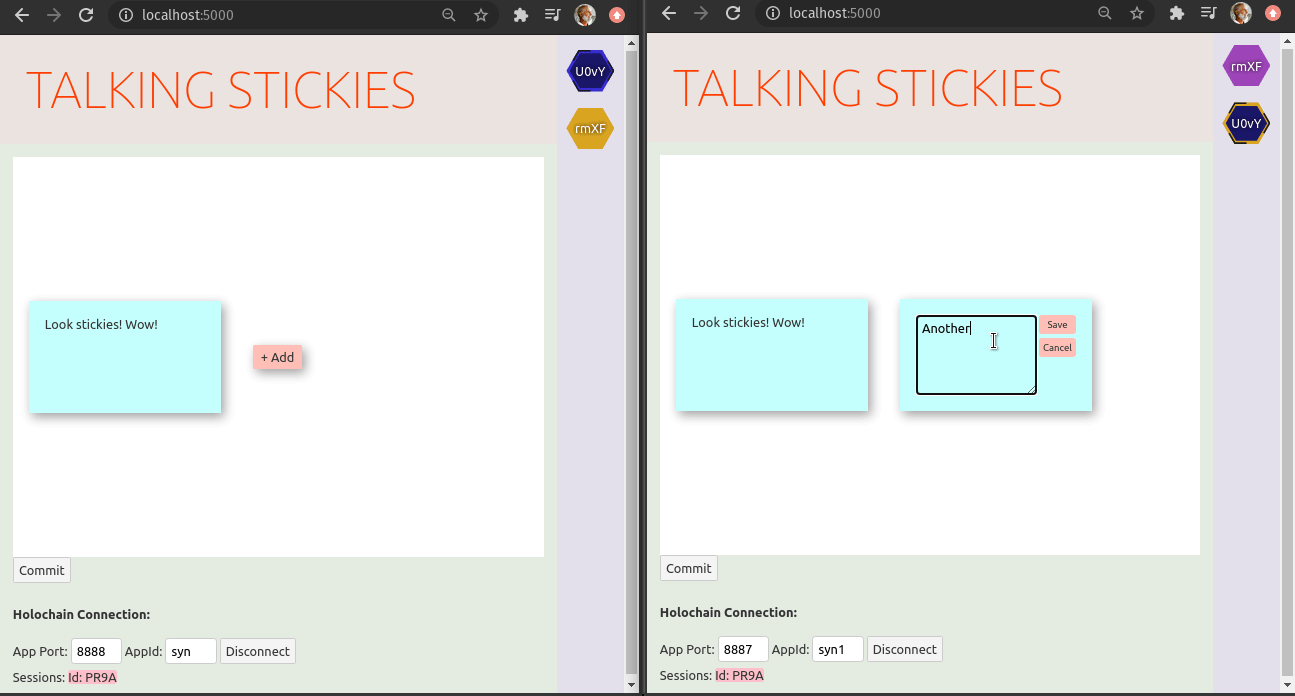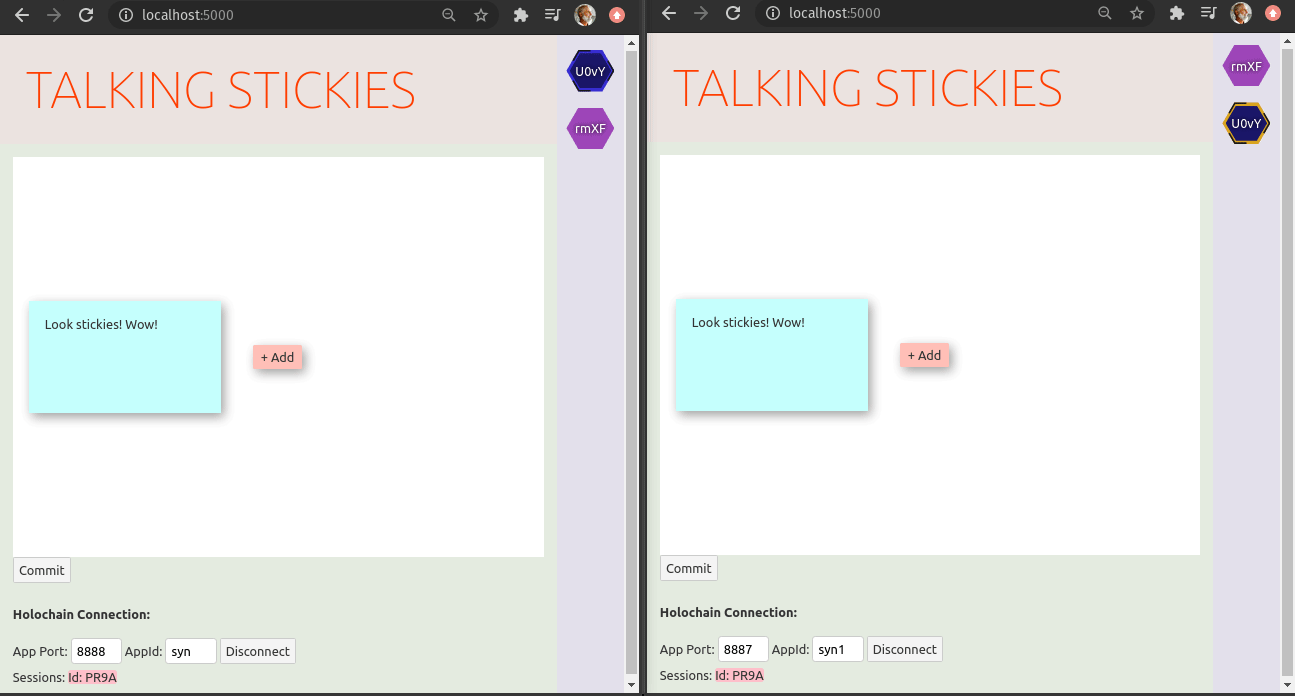 2021-03-03-bundles
2021-03-03-bundlesP.P.S. teaser for the hyper-nerdy reader:

P.P.P.S A number of folks helped with this article: Thanks first of all to Will for being a co-conspirator-in-syn-itself and for detailed edits and clarifications here. Thanks Jean Russell for supporting and pushing me to get this out, and especially for the initial draft of the comparison table. Thanks to Pospi, Guillem Cordoba, Siddharth Sthalekar, Hedayt Abedijoo, Emaline Friedman for comments edits and suggestions that made this article much better. And finally thanks to Art Brock for the usual co-creative sketching of things out that we can then turn into reality.
Das Blinken Bonken!
Seems like end of the year is DYI electronics projects time for me as the Sound Alarm happened round this time last year too. Well, I’ve been having a ball making Arduino stuff, this time as Christmas presents. This time I got my documentation act together even more and made a construction tutorial on instructables too! The code for Das Blinken Bonken is on github, and here’s a video of Jesse showing off the game:
Arduino Sound Alarm
I’ve just completed my second Arduino project, a sound level detector which sets off an “alarm” when there’s the sound level is to high for too long. I built it for use in a school that wants to provide visual feedback to students when they are being too loud. The “alarm” is a string of flashing LEDs that’s controlled by an IR-remote, which I reverse engineered using the the arduino itself and the excellent IRremote library to figure out which codes activate the LED string. The IRremote library includes an example that dumps the codes and code types that remotes typically use. So I just ran that example with my arduino hooked up to an IR detector from adafruit. It was really quite easy to do.
It’s been a fun project because it’s quite flexible and configurable. Here’s a short video of the finished product:
For anyone who wants to build one of these here’s a bread-board diagram that I made using the very cool Fritzing package:

The Adruino sketch that powers this is available on github.
Here are some details on the circuitry. The sound detector is based on the ZX-Sound board. Here’s a nice post on the arduino.cc site that I used as my starting place for building the sound part of this board. The video helpfully includes a parts list which I sourced from Allied electronics, all except for the mic. The LCD is the $10 16×2 from Adafruit (their tutorial on wiring it up was great), and I also used their electret microphone. One note about the microphone is that it’s polarity matters. If you get it in backwards, it’s much less sensitive. I found this out purely by accident! I also used their IR LED.
Here are some photos of assembling the project.
First the prototyping phase:

Then building the connector for the LCD:



Then drilling holes and installing the configuration controls (push-button and pot)


Then assembling and soldering the board with the sound circuit and the trim pot for the LCD as well as the resistor for the IR LED.


Finally, just before enclosing..

The completed project. Note that I left the mic and IR LED lose because I’m not sure exactly where the alarm is going to be installed and the way they face could matter.

Some lessons learned:
- When soldering a header for an LCD remember to take into account that if you copy the wiring order as you have plugged it into the bread-board, you will actually be doing it backwards because the connecter will be attached upside-down!
- You will need to drill a little extra hole in your case to accept the tab on the pot that keeps it from rotating when you spin the shaft.
- Electret microphones have a polarity.
- Hot-glue is great for attaching push-buttons.
- Ask you children for UI advice! Will had the excellent idea of using the setup-pot to spin between the different settings. In the original code I had it so you had to press the button to toggle between the setup parameters and then do a long-press to actually set one. The way it ended up is much better.
Parts List:
Arduino Uno: https://www.adafruit.com/products/50 ($29.95)
Makershed Arduino Enclosure: http://www.makershed.com/Clear_Enclosure_for_Arduino_p/mkad40.htm ($15.00)
9V powersupply: https://www.adafruit.com/products/63 ($6.95)
100K Potentiometer: Radioshack ($1.69)
pushbutton switch: Radioshack ($.99)
Breadboard PCB: https://www.adafruit.com/products/589 ($3.00)
Electret Mic: https://www.adafruit.com/products/1064 ($1.50)
IR LED: https://www.adafruit.com/products/387 ($.75)
LCD 2×16: https://www.adafruit.com/products/181 ($9.95)
Components: (~$5)
- resistors: 1k ohm x 2; 100k ohm x 2; 12 ohm; 39k ohm; 22k ohm; 230 ohm (for IR led)
- capacitors: 470uf 16v; 0.1uf 50v; 22uf 25v
- Dual op amp IC: TLC272
Total Price: ~$70
clojurescript syntax hilighting in emacs
To get emacs to syntax color clojurescript files (cljs) add this to your .emacs (or other emacs config file):
(setq auto-mode-alist (cons '("\.cljs" . clojure-mode) auto-mode-alist)) |
Upgrading postgres on Snow Leopard (Mac OS X 10.6)
Well, I too have gone down the rabbit hole of having to upgrade compiled-from-source apps to 64bit architecture after moving to Snow Leopard. The hardest by far was postgres. The sad thing is that 32bit version works just fine, but the adapter gems for rails don’t, hence the need for the recompile.
Mostly I followed this blog post, but it assumes that you had previously installed postgres using his instructions for Leopard which I hadn’t.
My previous installation was at /usr/local/postgres and these instructions end up installing it at /usr/local/pgsql, so my task also includes getting the data from my previous installation to the new on.
I also took some some hints from this post.
Here’s the blow by blow:
Make a backup of all my data from the 32bit version:
pg_dumpall > /tmp/32-bit-dump.sql |
Switch to super user, make a directory for the source (if you haven’t already), download and extract it:
sudo su mkdir /usr/local/src cd /usr/local/src curl -O http://ftp9.us.postgresql.org/pub/mirrors/postgresql/source/v8.3.8/postgresql-8.3.8.tar.gz tar -zvxf postgresql-8.3.8.tar.gz rm postgresql-8.3.8.tar.gz |
Now configure, make and install it:
cd postgresql-8.3.8 ./configure --enable-thread-safety --with-bonjour make make install |
Then I followed the instructions from the above mentioned blog on how to make a postgres user, but I did them in a different terminal window because remember the other one we were logged in as root:
“First, you’ll need to find an unused user and group ID. Use the following commands to list the IDs for the users and groups on your system.”
dscl . -list /Groups PrimaryGroupID | awk '{print $2}' | sort -n
dscl . -list /Users UniqueID | awk '{print $2}' | sort -n |
“For the purposes of this tutorial, let’s assume an ID of 113 for both the user and the group. Since the convention is to prefix system accounts with an underscore, use the following commands to create a user called _postgres:”
sudo dscl . create /Users/_postgres UniqueID 113 sudo dscl . create /Users/_postgres PrimaryGroupID 113 sudo dscl . create /Users/_postgres NFSHomeDirectory /usr/local/pgsql/ sudo dscl . create /Users/_postgres RealName "PostgreSQL Server" sudo dscl . create /Users/_postgres Password "*" sudo dscl . append /Users/_postgres RecordName postgres |
“Then, create the _postgres group:”
sudo dscl . create /Groups/_postgres sudo dscl . create /Groups/_postgres PrimaryGroupID 113 sudo dscl . append /Groups/_postgres RecordName postgres sudo dscl . create /Groups/_postgres RealName "PostgreSQL Users" |
So at this point the binaries are installed and there’s a user to run it under, but I needed to initialize a new database and copy back in my saved data. First create the data and log directories and set perms:
sudo mkdir /usr/local/pgsql/data sudo chown postgres:postgres /usr/local/pgsql/data sudo mkdir /usr/local/pgsql/log sudo chown postgres:postgres /usr/local/pgsql/log |
Then I logged in as the _postgres user:
sudo su su - _postgres |
And initialize database files and start up the database:
/usr/local/pgsql/bin/initdb -E UTF8 -D /usr/local/pgsql/data/ /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data/ -l /usr/local/pgsql/log/postgresql.log start |
Finally I restored the data from my initial pg_dumpall
/usr/local/pgsql/bin/psql -U postgres -f /tmp/32-bit-dump.sql |
I’ve also added these lines into my .profile to add the commands to my path and to simplify starting and stopping the database:
export PATH=$PATH:/usr/local/pgsql/bin export MANPATH=$MANPATH:/usr/local/pgsql/man alias pg_stop='sudo -u postgres pg_ctl -D /usr/local/pgsql/data stop' alias pg_start='sudo -u postgres pg_ctl -D /usr/local/pgsql/data -l /usr/local/pgsql/log/posgtres.log start' |
And then finally I could install the postgres rails gem (which was the whole point of this silly excercise):
sudo env ARCHFLAGS="-arch x86_64" gem install pg |